Scalability is key to high-performance computing. This paper will contrast and compare various examples of hardware that are used to achieve high-performance on scalable systems. Scalable hardware examples include Symmetric Multiprocessors (SMPs), Arrays (Clusters), Distributed Memory systems (MPPs), and Scalable Symmetric Multiprocessors (S2MP or CC-NUMA).
Definition of Scalability:
Scalable Computing enables computational power to be upgraded over a large range of performance, while retaining compatibility.
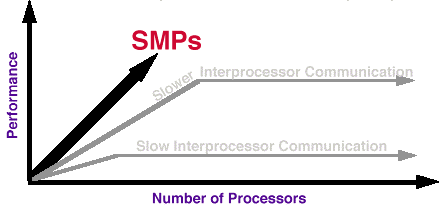
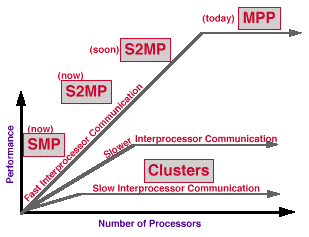
Scalability depends on the distance (time or latency) between nodes. A short latency (fast interprocessor communication) indicates a tightly coupled system, which is typically useful for capability solutions such as running large individual jobs. A long latency (slow interprocessor communication) indicates a loosely coupled system, which is typically useful for capacity solutions such as running many jobs on one system.
For a wide range of programs the number of processors across which an application will scale is related to the speed (latency and bandwidth) of the interprocessor communication. Very fast interprocessor communication is often a requirement in order to effectively use large numbers of processors (hundreds or thousands) in a single application.
Some applications are more sensitive to this communication speed than others. For example, prime number searches and other "embarrassingly parallel" applications work efficiently when distributed to thousands of PCs across the Internet with very low bandwidth and very long latencies. These latency-insensitive applications tend to millions or billions of calculations for each byte of data transferred. Another exception to this rule are applications which require a significant number of serial calculations which have limited scalability, regardless of the interprocessor communication speed (Amdahl's Law).
Many applications can run in parallel, but are sensitive to the speed of communication, such as codes for fluids, structures, chemistry and many other high-performance computing disciplines. For this large class of codes, as the number of processors increases on a fixed size problem, the work per processor decreases and the communication increases to a point where the communication speed becomes a limit on the scalability of the program.
Parallel programming techniques can be divided into two major classes: auto-parallel (actually semi-auto-parallel) languages and explicit parallel languages.
Auto-parallelism tends to require machines that support fine-grain parallelism. This typically takes some form of automatic parallel detection with assisting directives added by the programmer. This tends to be the simplest approach to parallelizing a code, but it can yield limited scalability. It is the technique of choice of a wide range of parallel applications that run on SMP hardware. This includes scientific libraries, fluids, structures, chemistry, and other common high-performance computing (HPC) codes.
Auto-Parallel Example
C The following loop is easy to auto-parallelize C Allocate iterations to many processorsDO 10 I = 1, 1000 DO 10 J = 1, 1000 A(I,J) = B(I,J) * C(I,J) + K10 CONTINUE
On the other hand, explicitly parallel programming tends to allow codes to run efficiently in parallel on a wider range of machines and on a larger number of processors. These techniques tend to allow the programmer to identify and use coarse-grain parallelism that may be difficult to exploit without some restructuring of the code. This requires more work to program in parallel, but often yields superior scalability when compared with more automated techniques. Examples of this class of applications are weather and climate models, LINPACK, electromagnetic and Monte Carlo simulations, and certain data pattern searches.
Explicitly Parallel Coding Example
C Run the following routines in parallel NW = ANALYZE_NW_QUADRANT() NE = ANALYZE_NE_QUADRANT() SW = ANALYZE_SW_QUADRANT() SE = ANALYZE_SE_QUADRANT()
Some parallel applications require random access to most of the application's memory regardless of the coding technique chosen. These programs are hard to partition into distributed pieces and have difficult load balancing requirements. For these programs, dynamic partitioning is a must and SMP style memories tend to assist this task, boosting performance. A classic example is crash analysis where the activity is concentrated in a small area of the object under analysis. For example, when a car crashes head-on into a wall, time spent analyzing the impact on the hood is productive while time spent analyzing the impact on the trunk may be wasted. Some progress has been made in running crash analysis on distributed memories, but this tends to work well only for simple cases.
Not all languages fit the simple binary classification of auto-parallel or message-passing. Languages such as HPF provide implicit coding techniques on distributed-memory hardware, with less programming effort than message passing. This is an exception to the general rule stated above that implicitly distributed (auto-parallel) codes tend to run on symmetric memories (SMPs) and explicitly distributed (message-passing) codes tend to run on distributed memories. The efficiency of HPF and other implicitly distributed languages is sometimes poor, but these languages are improving. The scalability of applications written in these emerging languages tends to be subject to the general rule that faster interprocessor communication enables higher scalability.
This paper will contrast the following four architectures:
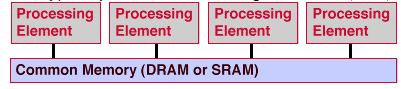
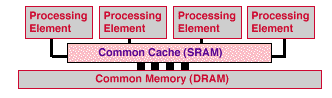
SMPs form the largest market segment for parallel computing. They tend to be the the easiest machines to program in parallel. All processor have equally fast (symmetric) access to memory and the programmer tends not to need to worry about the relation between the location of the processors and the memories.
These systems can be inexpensive to assemble, such as multiprocessor workstations and PCs. They tend to have limited scalability, typically 2 to 64 processing elements (PEs). The scalability is limited by the cost of maintaining a sufficiently high memory bandwidth from multiple processors to a single flat memory.
SMP performance depends on the latency to synchronize processors and the latency to communicate data among processors. The fastest SMPs use shared registers with tens of nanoseconds of latency. An example shared-register machine is the CRAY T90. A more common class of SMPs use shared cache without about 100 nanoseconds of latency. This class includes high-end workstations and servers. The slower SMPs tend to use shared memory without shared cache with hundreds or thousands of nanoseconds of latency. Examples are multiprocessor PCs and lower-end multiprocessor workstations.
SMP performance is strongly dependent on the bandwidth of the shared memory. Multiple processors exert heavy demands on this memory bandwidth. Bus based systems, such as most SMP workstations and PCs, may have low multiprocessor bandwidth. These systems show fast execution with data in cache, but exhibit slow random or strided access to memory.
Higher-end SMPs have multiport memories can have very high bandwidths. For example, the CRAY T90® has 880 gigabytes/second (GB/s) of memory bandwidth distributed across 32 CPUs @ 440 MHz per CPU. This is 8 words per clock per CPU, 8 bytes per word = 64 bytes/clock. (32 CPUs * 440 MHz* 8 words * 8 bytes/word = 0.88 TB/s!) Of course, this high bandwidth is not inexpensive.
Summary of SMP Scalability:
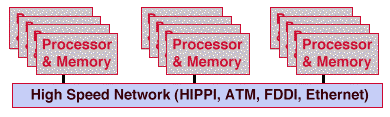
Arrays (AKA clusters) are the most popular highly-scalable architecture in the industry today. Any networked computer can participate in clusters. An extreme example is PCs on the Internet used to crack encryption keys or find large prime numbers. Clustering is a popular technique for scaling beyond the scaling limits of SMPs. Clusters are easy to assemble, but often hard to use for scalable capability applications.
Clusters tend to require course-grain parallelism for efficient parallelism to overcome the long latencies of interprocessor communication. They require many thousands, millions, or billions of instructions between communication cycles. They have no shared memory and therefore require message passing to span nodes (capability). They are often used for multiple serial-job throughput (capacity).
Their long latencies are typically tens, hundreds, or thousands of microseconds. Compare this with tens to thousands of nanoseconds for SMPs. SMPs typically have 100 to 1000 times better latency than clusters. Clusters also tend to have low interprocessor bandwidths: typically LAN or HIPPI speeds.
Low interprocessor bandwidth with long latencies means parallel programs tend to scale poorly on clusters. They do, however, provide good job throughput and latency insensitive programs can be scaled on these systems.
With clusters, one can easily to start small and then scale the hardware to larger configurations over time. One can add newer hardware to older hardware. The nodes can be individual compute nodes in addition to being members of a cluster. Clusters provide high reliability since parts of cluster can fail while others remain available. (One does not have to put all the eggs in one basket.)
Clusters are excellent for throughput (multiple single-PE jobs). for example, NQE can be used for scheduling multiple jobs across the various compute nodes in the cluster.
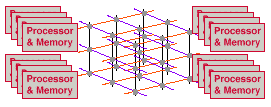
MPPs offer fast distributed memories that can scale to teraFLOP/s. One programs MPPs with message-passing primitives similar to cluster programming primitives, but MPPs are easier to program than clusters because MPP interprocessor communication often has a thousand times less latency with clusters. The interprocessor bandwidth also tends to be tens to thousands of times faster. In short, MPPs can be viewed as well implemented clusters that can scale a wider range of codes to hundreds and thousands of processors.
Easily programmed MPPs have fast distributed memories. This means low latencies 0.5 to 10 microseconds, which are typically 5 to 10 times longer than with SMPs but orders of magnitude faster than with clusters. It also means faster bandwidth, typically gigabytes per second of bisection bandwidth and often hundreds of MB/s processor to processor.
MPPs often have single-system images, minimizing the replication, administration, and system overhead. They also often offer global IO, where any processor and memory has a direct hardware path to any peripheral device. (Global IO can be important for easily programmed high-speed parallel IO.)
The CRAY T3E® systems are an example of MPPs that scale to thousands of processors with a low latency, high bandwidth interconnect, a single system image, and global parallel IO.
MPPs are the most highly scalable architecture available today.
Is the IBM SP-2® an MPP or a Cluster? It is a bit of both.
SP-2 MPP characteristics:
SP-2 cluster characteristics:
CC-NUMA - Combining SMPs and MPPs
Scalable Symmetric Multiprocessors (S2MPs) combine the rapid global memory access of SMPs with the scalable processing speed and memory bandwidth of MPPs. They can be programmed as SMPs, ignoring data locality, or as MPPs, with explicit data distribution.
S2MP systems can be programmed logically an SMPs, with global memory addressing, globally-coherent caches, and low interprocessor latencies. Every processor has fast and cache-coherent access to a common memory which allows SMP codes to run without modification or special directives. For example, the S2MP Origin 2000 systems are absolutely binary compatible with the SMP Power Challenge systems.
S2MP systems are made with MPP-like distributed processors and memories, but with coherency maintained among the distributed memories. This allows for MPP-like processor-speed and memory-bandwidth scalability. The MPP-like non-uniform memory bandwidth (NUMA) characteristics can be ignored when programming tens of processors with SMP-like code. The programmer tends to need to pay increasing attention to these NUMA characteristics as they scale the code to larger numbers of processors.
- Close to MPP Scalability
- Near-SMP global-memory performance
- Fully-compatible SMP logical memory behavior
SMPs are easiest to program than the other architectures listed in this paper. They have easy global IO. They are often the least expensive parallel solution. They are also the least scalable (limited to about 64 processors) and sometimes suffer from over driving the common memory from multiple processors. They can be programmed with auto-parallel or explicit parallel techniques but are usually programmed with the easier auto-parallel directives.
Clusters are good throughput engines but tend not to be good for scalable capability. They can be difficult to program using distributed-parallel programming message-passing techniques. They tend to have slow, difficult global IO. One rarely sees single system images on clusters.
Clusters advantages include easy reconfiguration, good resiliency, and good multiple-job throughput.
MPPs have demonstrated scalability to teraFLOP/s. They are easier to program than clusters (better latency) but harder to program than SMPs or S2MPs (non-coherent memory). MPPs support huge distributed memories (terabytes). Some MPPs have good global IO, others do not. Most have single system image operating systems.
S2MPs theoretically will scale to teraFLOP/s. Tens of GFLOP/s have been demonstrated to date. They have logically symmetric memory (SMP like) but physically distributed memory (MPP like). They have the SMP ease of programming (coherent memory) with message passing scalability. They support huge distributed memories (terabytes) with good global IO and single system images.
Scalability attributes:
R. Kent Koeninger is a Program Manager in the Software Division of Cray Research, a Silicon Graphics Company. Mr. Koeninger has 20 years experience in high-performance computing, including 5 years as a Program Manager at Cray for scalable systems and high-performance IO.