|
|
|
|
boisseau@sdsc.edu, allans@sdsc.edu, carter@cs.ucsd.edu
www.sdsc.edu
Cray vector computers have been the workhorses for scientific computing since the introduction of the Cray 1 in 1976. The ability to achieve high floating point performance on most scientific codes using a simple programming model has made them popular in the community. The CRAY X-MP was introduced in 1982 as the first Cray parallel-vector processor (PVP). The PVP programming model benefits from flat shared memory, which allows the programmer to concentrate on making the inner loop parallel (i.e., vectorizable) without worrying as much about domain decomposition and memory access patterns as the programmer of NUMA parallel machines (such as the CRAY T3E and Origin 2000). The PVP programming model also allows outer loop parallelism using multiple processors.
The 14-processor T90 at the San Diego Supercomputer Center (SDSC) is nearly fully 100% utilized with workloads consisting of computational fluid dynamics applications, computational chemistry codes, structural mechanics simulations, environmental modeling codes, and many others. Why haven't all users migrated to massively parallel processors (MPPs) such as the CRAY T3E, CRAY Origin 2000, and the IBM SP-2 that offer larger peak speeds and more total memory in larger configurations? These resources are available at SDSC and elsewhere and are, in fact, well utilized. However, many users continue to prefer CRAY PVPs. Among other reasons, these users find that the CRAY PVPs continue to give competitive performance on their codes and that it is much easier to develop and optimize applications for them than for the NUMA parallel machines.
The Tera MTA is a revolutionary new parallel computer designed around the multithreaded paradigm. It offers the promise of scalable performance with a large, flat, shared memory and a simple programming model. While it can benefit from inner and outer loop parallelism, it can also exploit parallelism at higher levels. Thus, potentially, it can perform well on codes optimized for the T90 as well as on non-vector codes.
Previous work [NASMTA] compared the performance of a single processor prototype of the MTA to a single processor of the T90. Since that time, we have begun evaluation of the first two-processor MTA. Also, the processor clock rate of our system has increased from 145 MHz to 255 MHz. Here we summarize improved performance of the MTA on NAS 2-serial benchmarks due to improved hardware and greater tuning effort. We then evaluate the MTA on three T90 workload applications: LCPFCT, a flux-corrected transport code; AMBER, a molecular dynamics code; and LSDYNA, a finite element code. We compare the single processor performance of the MTA and the T90 on each of these applications and show MTA performance on two processors for each.
The state of the Tera MTA at SDSC is still developmental. The two-processor system has been available for only several weeks, with time being shared between users and Tera staff. The programming environment tools are still being debugged and are updated frequently. The current operating system is a custom interim system provided by Tera until UNIX is delivered later this year. In a similar time frame we expect to increase the number of processors and their clock frequency, increase the memory and improve memory bandwidth, and install additional network boards which will decrease the memory latency in the interconnect. Currently, the clock frequency and the network boards are below specification. The interconnect, which attaches processors to memory, is not capable of keeping a program that accesses memory on every cycle operating at peak speed on 2 processors. While an embarrassingly parallel code that executes one memory reference per cycle should speed up twofold on the production network, it can only speed up by around 1.75 with the present network of our developmental platform. In any case, not all codes access memory every cycle, and the system is otherwise robust enough to proceed with evaluation. The hardware issues are manufacturing-related, not design-related, and will be corrected shortly.
Even though the MTA is still developmental and we have had it for very little time, we feel that this is potentially an important architecture and merits discussion at the Cray User Group Meeting in Stuttgart. We have not had sufficient time to do a rigorous, comprehensive benchmarking comparison of the MTA vs. the T90 (such results will be presented at SC98), but we have had time to compare the single processor on a handful of standard benchmarks and applications. We have also been able to observe how the MTA performs on two processors on some applications, subject to the constraint of the developmental network mentioned in the previous paragraph. We hope that readers will appreciate these early observations and comparisons subject to these caveats.
Table 1 summarizes some basic hardware characteristics of the T90 (T916 chassis) and the MTA:
CRAY T90 |
Tera MTA |
| 440 MHz frequency 8 128-element vector registers per CPU Dual vector pipes into functional units Pipelines ADD and MULTIPLY units Can execute 4 flops/cycle (commonly 2) Flat shared memory SRAM, high bandwidth, low latency Can issue 2 loads + 1 store / cycle |
300 MHz clock (currently 255MHz) 128 Streams (hardware for threads) per CPU Effective depths of streams into functional units is 21 Additional Fused Multiply-Add (FMA) functional unit Can execute 3 flops/cycle (commonly 2) Flat shared memory SDRAM, moderate latency, moderate bandwidth Can issue 1 memory reference / cycle |
| Peak 1.76 GFLOP per CPU Practical Peak of 1 Gflops Currently observe 400-800 Mflops in 'good' user codes |
Peak 0.9 Gflops per CPU Practical peak of 600 Mflops Tera claims sustained 30-60% of peak in 'good' user codes |
Table 1: Basic Hardware Characteristics of T90 and MTA.
As can be seen, the clock of the T90 is faster. Also, the T90 is capable of more than one memory reference per cycle once the vectors are filled, while the MTA can perform only one memory reference per cycle. These facts give the T90 a distinct advantage on vector codes.
The T90 can execute 4 floating point operations in a single cycle due to its chained ADD and MULTIPLY functional units and dual pipes. The MTA can issue three in a VLIW (very long instruction word) per cycle. It is not common to see observed performance in applications at these peak rates on either machine.
The T90 compiler vectorizes inner loops (without vector dependencies), exploiting inherent parallelism for such loops. The compiler can parallelize over outer loops using multiple processors (once again assuming no dependencies), but the fundamental level of parallelism--the potential for greatest performance gain--occurs at the inner loop level of vectorization. If the inner loop is not efficient, the T90 cannot generate efficient multiprocessor code.
The MTA compiler can decompose parallel loops into threads. It can do this for inner or outer loops. If the potential for parallelism in inner and outer loops is comparable, the compiler will parallelize outer loops to reduce overhead [BLASTUN]. Because outer loop parallelism can be more efficient, restructuring codes can lead to increased performance on the MTA. The programmer has ultimate control over the method of parallelization. The MTA keeps the context of up to 128 threads in hardware called streams ready to execute on the processor. It can switch context each cycle and so keeps the processor saturated. If one thread cannot execute (due, say, to an outstanding memory reference), then an instruction from a different ready thread is issued. Each thread can issue only once in 21 cycles. This means that a minimum of 21 threads is required to keep the processor saturated. Figure 1 illustrates the logical view of an MTA processor and how streams are used to keep the instruction pipeline filled.
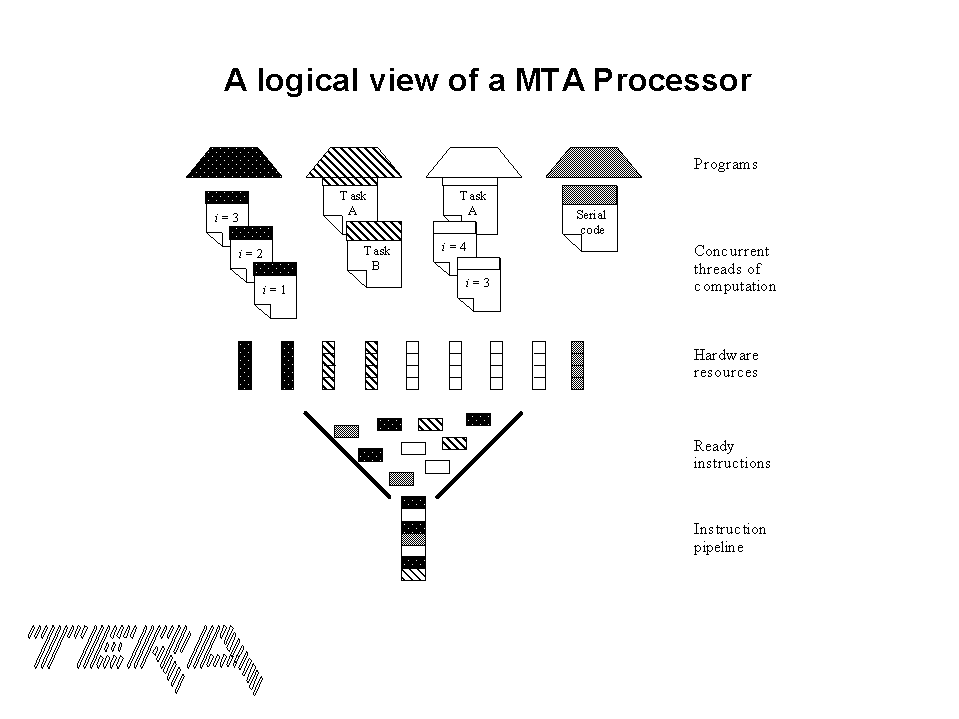
Figure 1: Logical view of the MTA processor.
The T90's flat memory is high-speed SRAM. The T90 has to minimize latency and maximize bandwidth to fill the vector registers. The MTA's flat memory is SDRAM, with somewhat higher latency and lower bandwidth. Latency on both machines is a function of memory technology and memory router (interconnect) technology. It takes about 55 cycles to get the first value back from memory when the T90 starts to fill a vector unit. It takes about 140 cycles for the MTA to get a value back. However, the MTA is designed to tolerate latency by finding something else for the processor to do while waiting for an outstanding memory request to come back. This is the crucial design concept in the multithreaded architecture: parallel programming on shared memory can be easy and efficient if the processors can be kept busy by hiding the latency of the shared memory accesses.
A useful preamble to discussion of performance numbers for benchmarks and applications is to consider, for a moment, simple loops that perform well on each machine.
Developing optimal code for the T90 requires loading the vector registers with long arrays, making full use of the chained ADD and MULTIPLY functional units and re-using the vectors within the same loop to amortize the vector load startup. For peak performance, code should not execute more than 2 loads and 1 store per line, and the ratio of flops to memory references should be kept small within loops by re-using arrays already stored in vector registers. We want fully vectorizable expressions rather than reductions. Here is an example loop:
do i = 1, NMAX
z1(i) = const1*x(i) + const2*y(i) + const3
z2(i) = const2*x(i) + x(i)*y(i) + const3
z3(i) = const3*x(i) + y(i)*y(i) + const1
z4(i) = const4*y(i) + x(i)*x(i) + const2
end do
where NMAX is some very large integer (several times the vector register size). This code has 16 flops and only 6 memory references. One would expect nearly the peak performance of 4 flops per cycle for a rate of 1.76 Gflops (a little less due to load time for the arrays). We timed this loop at over 1.6 Gflops.
To get an idea of what kind of code would perform well on the MTA, consider the MTA VLIW, which can be encoded M.A.C. for Memory.Arithmetic.Control. The compiler attempts to fill each of these three slots of the VLIW so that, when the VLIW is executed, a memory access, an arithmetic operation (including potentially a Fused-Multiply-Add, or FMA, which executes two flops) and a control operation (branch test or jump) is performed. If the compiler cannot fill a slot, it inserts a null operation (NOP). Under certain circumstances the compiler can put a second arithmetic operation in the control slot such as an ADD (but not a FMA). Thus, a sequence of 'well packed' VLIWs would have one memory operation and up to three flops (one FMA and one ADD) per cycle. With a clock speed of 255 MHz we could expect close to 765 Mflops on one processor for ideal code.
Consider the following loop: counting flops and memory accesses, we find 12 flops and 4 memory reads per iteration. Of course, there is an implied loop increment and branch test as well. The Tera tool CANAL (for 'Code ANALysis') generates an annotated version of the source describing the instructions generated for each loop, the loop scheduling mechanism, and an estimate of the hardware resources needed. In the example below, we see that the 4 memory operations and 12 floating point operations have been packed into 6 instructions, with 25 streams needed. To overcome the loop overhead, it was necessary to reuse memory references in more than one expression calculation.
do i = 1, NMAX
sum1 = sum1 + A(i)*B(i) + 1.0
sum2 = sum2 + A(i)*C(i) + 1.0
sum3 = sum3 + B(i)*C(i) + 1.0
sum4 = sum4 + A(i)*D(i) + 1.0
enddo
Canal Output Loop scheduled: 4 memory operations, 12 floating point operations 6 instructions, needs 25 streams for full utilization
We initially expected to achieve nearly the theoretical maximum speed for this loop, assuming that each line would be executed in a fully packed VLIW with one FMA and one ADD, with enough loop unrolling to amortize the cost of the loop test and increment. In fact, when run on one processor, this code obtains 485 Mflops. The CANAL output shows that the assembly code has 12 flops per 6 memory references, indicating a peak performance for this loop of 2 flops per cycle or 510 Mflops on our 255 MHz processors. Thus, the loop achieved nearly the performance predicted by CANAL, but not what we initially expected if the code achieved three flops per cycle. We are still exploring why this loop failed to achieve an even greater percentage of theoretical peak performance.
The CANAL output also tells us that 25 streams were required for full utilization of the processor. For 'ideal' code, in which there is sufficient instruction level parallelism (ILP), only 21 streams are needed--the minimum number possible due to the effective depth of the pipeline. Code with essentially no ILP--each instruction depends on the result of the immediately previous instruction--would require a number of streams equal to the memory latency in cycles (140). The MTA has only 128 streams per processor, relying on the fact that essentially all code, especially all code with any inherent parallelism, has some ILP. If the average ILP is at least 7 instructions, then 21 streams are sufficient. (At least 21 streams are always needed even if the ILP is greater than 7 due to the effective depth of the pipeline.) Thus, the average ILP of the loop above appears to be something less than 6: 140 cycles divided by 25 streams = 5.6, the average ILP of this loop.
In [NASMTA] the extrapolated performance of a single-processor MTA running at 333 MHz (which was the initial projected clock for the production MTA) to that of one processor of the T90 on the NPB 2.3-Serial benchmarks (kernels only, not applications) was reported. These benchmarks are derived from the 'regular' NPB 2.3 benchmarks for parallel machines, which were written using MPI, then stripped of the MPI calls to produce serial versions. Thus, these benchmarks have not been optimized for vector or multithreaded computers.
The [NASTMA] results using the 145 MHz MTA prototyped were scaled up to 333 MHz and showed that the MTA would be competitive. Architecturally, the MTA can generate results at the clock speed as long as sufficient streams are available to cover the latency of loading instructions and data for each stream. Now, with a 255 MHz clock, we can verify the validity of the scaling assumptions in [NASTMA] and compare results versus the T90 head-to-head with real performance numbers. In fact, the MTA runs slightly faster than originally predicted in [NASTMA] on all benchmarks. This shows that the architecture has scaled gracefully as the clock has been increased. The MTA clock should reach the 300 MHz range.
Table 2 shows the T90 a clear winner on the multi-grid kernel MG, which is naturally a highly vectorizable code. The MTA is a clear winner on the integer sort kernel IS (for which it is the record holder on the NPB 1 IS benchmark). The performance on the other three kernels is comparable, with the MTA projected to have a slight edge on each when the clock is ramped up to 300 MHz. (Note: our current 14 processor T90 is actually about 15% slower on a single processor basis than the T94 configuration used in [NASMTA] due to a slower clock speed, 440 MHz vs. 450 MHz, and, more significantly, a slower memory subsystem in the T916 chassis.)
|
Benchmark |
CRAY T90 |
Tera MTA |
Tera MTA (300MHz) |
| CG |
176 Mflops |
171 Mflops |
201 Mflops |
| FT |
177 Mflops |
166 Mflops |
195 Mflops |
| MG |
519 Mflops |
237 Mflops |
280 Mflops |
| EP |
7.51 Mops |
7.57 Mops |
8.9 Mops |
| IS |
62 Mops |
83 Mops |
98 Mops |
Table 2: NPB 2.3-Serial performance on kernels
Note that, to date, most of our tuning efforts have been exerted on the MTA (the architecture we know least about). The T90 versions were not tuned significantly, although the random key generator in EP was vectorized. In the coming months we intend to exert tuning effort on the T90 as well, for both single and multiple processors. (We will use the serial versions as the starting points for our multiprocessor optimization on both platforms as well because they are more appropriate for the parallelism exploited by both platforms.) We will present these results at SC98.
LCPFCT is a group of Flux-Corrected Transport (FCT) fluid dynamics algorithms with fourth-order phase accuracy and minimal residual diffusion [LCPFCT]. All of the inner loops vectorize. LCPFCT is a one-dimensional solver, but multidimensional problems can be solved by timestep splitting.
Table 3 shows the performance of two sizes of an LCPFCT problem on one processors of the T90 and the MTA. We also ran the problem on two MTA processors to see how the performance would scale with the prototype network. The test problem, called FAST2D, is a two-dimensional muzzle flash problem in which a high density gas inside a tube, or barrel, is allowed to expand rapidly down the barrel and out into the ambient medium. We executed two simulations, one at 400x400 cells and one at 800x800.
|
Test |
CRAY T90 |
Tera MTA |
Tera MTA |
| FAST2D-400 (avg. VL=80) |
387 Mflops |
241 Mflops (284) |
433 Mflops (510) |
| FAST2D-800 (avg. VL=104) |
498 Mflops |
256 Mflops (303) |
458 Mflops (540) |
Table 3: LCPFCT Performance on FAST2D test problem
Values in parenthesis for MTA represent expected performance with 300 MHz clock. Our experience in scaling results from the 145 MHz prototype to the current 255 MHz clock leads us to believe that performance for this architecture can improve essentially linearly with clock frequency as discussed in the previous section.
The MTA single processor performance is better than the ratio of clock speeds would predict. This is because the MTA makes use of inner loop (vectorizable) parallelism and time-step splitting (outer loop parallelism.) To achieve this, the driver, which solves a 2D muzzle flash problem by calling 1D LCPFCT, had to be modified to eliminate false dependencies on scratch arrays in common blocks. The appropriate level of parallelism for this problem is over rows when columns are being integrated and vice versa, but this level of parallelism occurs two subroutine levels higher in the source code (not in an outer loop immediately surrounding the inner loop). Nevertheless, this was simple to implement on the MTA.
LCPFCT is a highly vectorized code and performs very well on the T90, especially for large problems. The MTA is less sensitive to vector length as it can exploit outer loop parallelism to make up for lack of work in the parallel inner loops. The MTA single processor performance is comparable to the ratio of the clock frequencies. The MTA speedup on two processors is 1.8, which is as good as can be expected for this memory-intensive problem on the current memory network (see section 2). The T90 is the overall winner on a single-processor basis, but the MTA two-processor results will surpass the T90 single processor when the clock is increased to 300 MHz.
The AMBER (Assisted Model Building with Energy Refinement) molecular dynamics (MD) package, has been jointly developed by Peter Kollman at UCSF and David Case at TSRI [AMBER]. MD is a method of obtaining a statistical sampling of molecular structures by integrating Newton's equations of motion over time. It is a classical mechanics method, but is the only way to generate a simulation over a long period of time for large structures, given the severe limitations on the size of problems that can be treated using quantum mechanical calculations.
AMBER consists of many modules, most of which are used to prepare data files for simulations and to analyze the output. However, two modules account for the majority of the CPU usage. These are SANDER (Simulated Annealing with NMR Defined Energy Restraints), which performs energy minimization and MD simulations, and GIBBS, which is used to calculate the free energy change of reactions. These codes use the same set of routines to calculate the inter-particle force fields, and it is these routines that in turn use most of the CPU time.
The following table shows the performance of the T90 and the MTA on a simulation of a plastocyanine molecule in a vacuum (PROVAC).
|
Test |
CRAY T90 |
Tera MTA |
Tera MTA |
| PROVAC (avg. VL=71) |
306 Mflops |
196 Mflops (230) |
270 Mflops (318) |
Table 5: AMBER performance on PROVAC test problem.
The critical loop for all of these calculations is in the routine called NONBON. NONBON loops over all of the atoms in the problem, determining distances, energies, etc., for every other atom with which the atom interacts in vectorizable inner loops. This code ported easily to the MTA. Following the dictum that "MTA prefers outer loop parallelism," initial tuning efforts focused on flattening the double-nested NONBON main loop. In this case, the effort proved counterproductive, as the small inner loops were easier for the compiler to unroll and pack, so the final parallelization involved very little modification after all. Again, locks were replaced with fine grain synch variables.
AMBER is a good performer on the T90. The MTA obtains comparable performance relative to its clock speed on one processor. In this case the MTA exploits the same parallel features of the problem as the T90 and does not find a lot of new ones. On two processors, the MTA scales at somewhat less than the limit imposed by the pre-production network. However, it does manage to generate a result that should slightly outperform the T90 on two processors when the clock is increased to 300 MHz.
LS-DYNA3D is a general-purpose, explicit three-dimensional finite element program used to analyze the large deformation response of inelastic solids and structures. LS-DYNA3D was developed by Livermore Software Technology Corporation (LSTC), founded by John Hallquist who had developed the original LS-DYNA3D program at Lawrence Livermore National Laboratory [LSDYNA]. LS-DYNA3D is an engineering design tool for modeling the nonlinear, transient response of complex structures. State-of-the-art applications with LS-DYNA3D include metal forming, earthquake, and highway safety models, and other transportation research models combining recent research in materials science. DYNA3D is used in engineering design groups in over 400 companies in the United States and is available on computer systems ranging from workstations to vector supercomputers.
The following table shows the performance of the T90 and MTA on a crash simulation. The C2500/NJ dataset for this run, obtained from the National Crash Analysis Center (NCAC), simulates a truck sideswiping a New Jersey highway barrier with airbag deploying. In such a scenario, there are many small components (steering wheel, bumper, dashboard, etc.) and a lot of contact calculations as the truck deforms and slides along the barrier and deploys the airbag. The contact calculation is an integer sort on XYZ coordinates that is hard to vectorize. The T90 can perform at over 600 Mflops on LS-DYNA3D when the vectors are long and there is little contact [CHARMAN], but in contact problems the T90 is not particularly efficient.
|
Test |
CRAY T90 |
CRAY T90 |
Tera MTA |
Tera MTA |
| C2500/NJ (avg. VL=62) |
154 Mflops |
227 Mflops |
105 Mflops (124) |
171 Mflops (202) |
Table 4: LS-DYNA3D performance on C2500/NJ test problem.
Tuning LS-DYNA3D for the MTA required very little modification to the code. We started with an autotasked vector version for the C90 and T90. The MTA compiler understands Cray directives. Autotasking becomes outer loop parallelism, and vector loops become inner loop parallelism. On the MTA these levels are handled in exactly the same way, becoming candidates for decomposition into threads. The compiler may, however, choose to keep parallel inner loops in the same thread to exploit ILP (Instruction Level Parallelism) when there is sufficient parallel work at the outer level. In the vector version, the inner loops are broken up into chunks whose number of iterations is equal to the vector unit length of the machine. The MTA compiler, which does intensive loop restructuring, likes smaller chunks, which it can more easily unroll and pipeline. The inner loop iteration count sweet spot on the MTA is 16. Updating of shared arrays requires the use of locks for vector multitasking. The MTA employs bits on each word of memory to provide lightweight, fine grain synchronization. This allows multiple threads to update the same shared array (as long as they don't update the same element) at the same time. This improves concurrency in update loops. Locking update regions in the multitasking code were converted to MTA style "read on full, write on empty" instructions.
The T90 performance was not very good due to the small average vector length of this problem and the fact that a major portion of time in spent in a sorting algorithm (both are inherent features of contact problems in LS-DYNA3D). The MTA performance was better than the ratio of clock frequencies. The MTA is less sensitive to sort vector lengths as it exploits parallelism in a more general way. In addition, the superior performance of the MTA on the IS benchmark implies that it might scale well on a problem which uses a significant percentage of time in a sort operation. The MTA results scaled to two processors at the limit allowed by the prototype network board, which was still greater than the scaling of the T90 results.
It is too early to declare a 'champion'. The MTA is still a prototype and does not have its final processors or network. However, we can draw some potentially valuable insights from the work accomplished so far, while we continue to evaluate the maturing MTA system and prepare a more comprehensive comparison for SC98.
The T90 is a fast machine that is easy to program and is well suited to vector codes. It is relatively straightforward to write loops that can achieve nearly the peak performance of the machine, and therefore to develop codes that achieve a reasonable fraction of this peak. Our benchmarks and applications tests are generally consistent with the 25-50% of peak performance obtained by NPACI users. The T90 is also a capable parallel processor, although performance is still limited by the efficiency of the vectorization obtained in the inner loops. The autotasking option, while potentially powerful, does not allow the user fine control over load balancing. (Handcoded autotasking allows some finer control, but was not explored in detail here. We will explore this more in subsequent work when OpenMP is available for the T90.)
Porting T90 codes to the MTA is easy. The MTA can exploit the same parallelism that the T90 can exploit. It can also exploit levels of parallelism that the T90 does not. The MTA gives good performance and scalability on T90 workloads, and for some T90 applications (such as LS-DYNA3D) is expected to give superior performance on many processors.
Excellent compilers and simple programming models facilitate tuning on both platforms. The T90 is still the world's fastest vector machine, but the MTA may outperform it across a wider spectrum of codes involving outer-loop and higher level parallelism.
As we gain experience on the MTA and the tools mature, we will continue to optimize the NPB 2.3-Serial benchmarks for the MTA and will tune for the T90. We will do this for multiple processors as well as single processors for both platforms and will include the applications as well as the kernels. These results will be presented at SC98.
We will begin testing AMBER and LS-DYNA3D with larger test problems. We will also port other applications to the MTA, such as GAMESS (quantum chemistry code), OVERFLOW (fluid dynamics simulations), and MPIRE (volume rendering application). If you have suggestions for applications that should be well suited to the MTA, please contact Allan Snavely (allans@sdsc.edu).
We are obliged to Jerry Greenberg of SDSC for his expert advice and assistance on AMBER; Chuck Charman of SDSC for his expert advice and assistance on LSDYNA. Lawrence Miller of NCAC provided insight on performance of crash codes on vector machines. Don Thorpe, Cray administrator at SDSC, was invaluable to these efforts. We thank each of the above.
This work was supported in part by NSF award ASC-9613855 and DARPA contract DABT63-97-C-0028.
[AMBER] http://www.amber.ucsf.edu.
[BLASTUN] P. Briggs "Tuning the BLAS for the Tera", M-TEAC '98 Conference Proceedings.
[BRIGGS] P. Briggs, personal correspondence.
[CHARMAN] C. Charman, personal correspondence.
[LCPFCT] J. Boris, A. Landsberg, E Oran, J. Gardner "LCPFCT-A Flux-Corrected Transport Algorithm for Solving Generalized Continuity Equations", NRL/MR/6410--93-7192.
[LSDYNA] http://www.lstc.com.
[NASMTA] J. Boisseau, L. Carter, K. Gatlin, A. Majumdar, A. Snavely "NAS Benchmarks on the Tera MTA", M-TEAC '98 Conference Proceedings.
![]()
