|
|

Link to slides used for this paper as presented at the conference. They are in Acrobat PDF format.
|
|
![]()
GRD originated from a joint development of Raytheon Systems Company (formerly E-Systems) of Garland TX, Instrumental Inc. of St. Paul MN, and GENIAS Software GmbH of Neutraubling Germany. The product is unique in its approach to provide more effective management of distributed computer systems. This article describes the product's origins, capabilities, benefits, and applications.
GRD is intended for computing centers in need of more effective resource management and policy administration and, in particular, heterogeneous or homogeneous UNIX environments that involve multiple major shared resources. GRD leverages complementary technologies of three companies to bring about major improvements over existing products including:
* Higher resource utilization and throughput (and associated ROI)
* Reduced administrative and operational workloads
* Improved level-of-service and higher productivity for users
These improvements result from the unification of three primary capabilities:
These technologies are tightly integrated to provide a unique solution to the complex resource management needs of shared resource centers while offering many advanced features including:
 Figure 1: GRD Extends the CODINE Job Management System
Figure 1: GRD Extends the CODINE Job Management System
The material that follows discusses the issues that have heretofore limited the effectiveness of workload management systems along with details of the GRD approach.
Workload management is the process of controlling the use of shared computer resources to maximally achieve the performance goals of the enterprise (e.g., productivity, timeliness, level-of-service). This is accomplished through resource management polices and tools that strive to maximize utilization and throughput while being responsive to varying levels of timeliness and importance.
To accomplish these goals, management solutions must utilize the relative importance of competing jobs and correlate concurrent instances of the same users, jobs, projects, etc. in order to implement effective resource sharing policies. Systems that lack this sophistication will have inherent weaknesses in mediating the sharing of resources such as:
These limitations lower overall resource utilization, reduce throughput performance (especially when relative priority is considered), and increase the need for operational or administrative intervention.
Furthermore, initial job placement occurs at a single point in time and cannot take natural and unforeseen dynamics into account. Actual resource usage can diverge significantly from desired usage after dispatching. Therefore, dynamic re-allocation of resources is a prerequisite to optimal workload management.
To avoid improper dispatching of jobs, GRD performs resource tasking based upon the utilization and collective capabilities of an entire system of resources and with complete awareness of the total workload. Jobs executing anywhere in the pool of managed resources are correlated with users, projects, departments and job classes in determining how to allocate resources when new jobs are submitted or complete.
The following table displays the drawbacks of current queuing system implementations with respect to resource tasking (the dispatching decision). The table shows how these issues are resolved in GRD and which benefits are obtained by using GRD.
| Current Implementations | Resulting Limitation | Solution | Results | Benefits |
|
* No correlation among multiple instances of same user, project, department, job class, etc. * Spawned processes not counted in workload associated with job * Current resource loading is primary parameter for job placement |
* Users inadvertently dominate resources * Important work does not get appropriate share of resources * Poor job placement/load balancing * High importance work not properly distributed * Proper precedence not implemented in dispatching sequence |
* Global view of resources and workloads with all workload elements properly correlated * Proportional dynamic scheduler * Multiple resource management policies * Dispatching decisions consider global resource shares, resource loading, intended usage, and resource capabilities * Dispatching precedence based on resource entitlement * Global redistribution of tickets after dispatching and/or job completion |
* Utilization by specific users, projects, departments, etc. stays aligned with policy * More optimum fit of workload priorities to resources * More urgent work handled accordingly * Reduces need for manual intervention * Reduces need for job migration |
* Higher effective utilization of resources * System more responsive to relative importance of jobs and workloads * Improves/automated control of long term usage * Users more satisfied with level of service * Reduces administrative and operational workloads |
Table 1: Solving Current Resource Tasking Issues
But GRD does not only take resource utilization policies into account when dispatching jobs. GRD continuously maintains alignment of resource utilization with policies using a dynamic workload regulation scheme. GRD monitors and adjust resource usage correlated to all processes of a job, the corresponding job classes, users, projects, and departments. Operational adjustments to resource entitlements are centralized and take effect globally because of workload correlation and workload regulation.
The following table shows again drawbacks of current static scheduling tools as opposed to GRD´s dynamic workload control..
|
Current Implementations |
Resulting Limitation |
Solution |
Results |
Benefits |
|
* Little or no automated control of workload execution after dispatching * Use of priority without workload regulation * Workload elements not correlated across resource pool |
* Actual resource utilization diverges from intended utilization * Unreliable relationship between control parameters and workload performance * Excessive manual intervention * Unnecessary deferred execution of demanding jobs * Resources under-utilized |
* Continuous monitoring of resource utilization * Global view of resources and workloads with all workload elements properly correlated * Ticket-based scheduler and proportional dynamic resource manager able to redistribute work shares * Utilize low level controls for controlling workload performance * Centralized override control |
* Utilization by specific users, projects, departments, etc. stays aligned with policy * More urgent or more important work given appropriate share of resources * Reduces need for job migration * Reduced need for manual intervention * Demanding low priority jobs can be submitted early to take advantage of unused capacity |
* Higher effective utilization of resources * System more responsive to relative importance of jobs * Improved/automated control of long term usage * Users more satisfied with level of service * Reduces administrative and operational workloads * More effective controls for administrative and operational intervention |
Figures 2 and 3 depict in further detail the difference between static scheduling as performed by current state-of-the-art resource management systems and the dynamic scheduling scheme implemented by GRD in order to solve the problems described above.
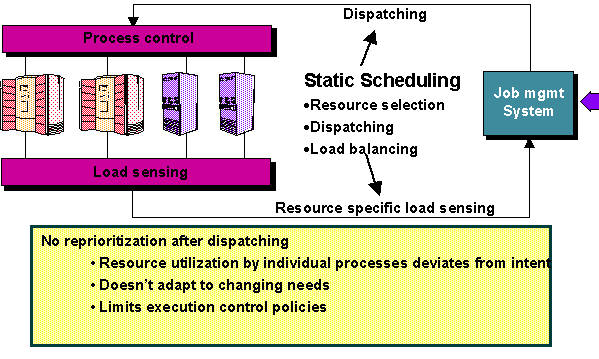 Figure 2: Workflow of current tools with static scheduling
Figure 2: Workflow of current tools with static scheduling 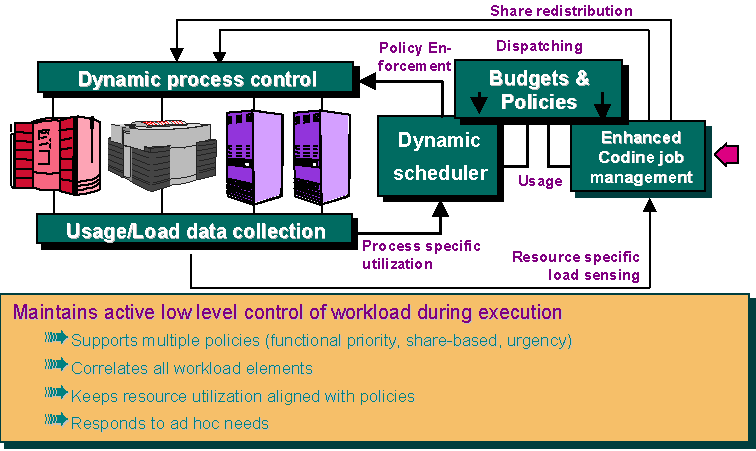 Figure 3: GRD workflow with dynamic scheduling feed-back loop
Figure 3: GRD workflow with dynamic scheduling feed-back loop
In order to be capable of adapting to a large variety of site specific resource utilization requirement GRD will schedule jobs using a weighted combination of policies:
* Functional--Supports relative weighting among users, projects, departments, and job classes during execution
* Initiation deadline--Automatically escalates a job's resource entitlement over time as its deadline nears
* Override--Adjusts resource entitlements at the job, job class, user, project, or department levels
* User discretionary--Allows users to adjust relative importance of jobs within a user's workload
These policies can be combined as depicted in figure 4 using GRD´s ticketing system. Each policy is assigned a total amount of tickets which defines the relative level of importance of the policies. Tickets can be compared with stock shares - the more shares a stock owner has, the more influence s/he has.
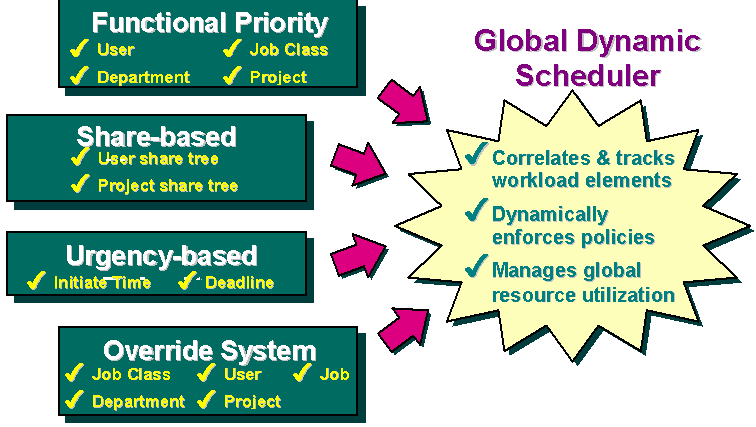 Figure 4: GRD Resource Utilization Policies
Figure 4: GRD Resource Utilization Policies
While the relation between the different policies is defined at the top level, the policies internally collect resource usage for users, projects, departments and job classes and GRD arbitrates the usage against the policies as defined by the site management. Thus when a single user (or project or department) will submit many jobs, other jobs that the user (or project or department) has in execution will receive fewer share allocation in order to keep associated resource usage at the appropriate level. Conversely when a job completes, the resource entitlements of other executing jobs for the associated user are escalated.
In determining dispatching precedence GRD will favor jobs with larger resource entitlements reflecting the fact that larger entitlements indicate higher importance.
BMW has been using CODINE and later GRD since 1994 to distribute computing workload for crash simulations. GRD is today installed on 11 SGI Origin server systems and more than 100 SGI workstations with altogether 370 CPUs. The following sections sum up the benefits for BMW, document the changes in the computing environment and tells about future plans.
 Figure 5: Automobile crash simulation at BMW using GRD
Figure 5: Automobile crash simulation at BMW using GRD
The BMW Crash department EK20 performs compute-intensive crash simulations with PAM-CRASH. The results are heavily used in the design process of the vehicles. Back in 1994 the environment was very simple - computational work was done on 10 CPUs by 3 engineers. Users resorted to "phone call scheduling", which was not a problem with just a few users.
The department was growing rapidly, and "phone call scheduling" was no longer possible. A second compute server was installed; thus it was necessary to provide transparent access for users. BMW identified this as being a crucial problem with multiple servers. The crash department wanted the CPU load to be equally distributed without any servers being overloaded. Also monitoring capabilities of resource management systems were considered as important so as to being able to see at a glance if something is wrong with a machine.
CODINE was installed at a very early stage of automated job distribution. Therefore, the BMW crash department never experienced problems in managing the enormous growth of the cluster. The department grew by a factor of 10. The number of CPUs used now is about 370 on 11 compute servers and more than 100 workstation - still increasing. The applications have become more complex, the number of test cases and the variations per model have grown exponentially. BMW feels that they would not have been able to manage this growth without the help of CODINE/GRD.
Today, about 45 users submit jobs to the cluster, utilization is far more than 80% of the total CPU time, downtimes included. CODINE/GRD has optimized the utilization of the machines and thus reduced new purchases to a minimum. So there is a direct connection to savings.
Counting only the reduction of purchases, BMW estimated savings of more than 1 Million US$. As an indirect consequence, there was a speedup in simulations, and the crash department engineers were able to focus on their scientific business instead of IT processes. In summary, development cycles for BMW products were shortened.
Current activities focus at making use of the dynamic resource utilization management facilities of GRD. It allows a flexible priority enforcement according to a project's budget. Furthermore, an additional increase in utilization to an overall 90% is expected. This is being approached by starting low-priority jobs during the day. During the night, when the urgent tasks have finished, these jobs will gain more priority.
The BMW crash department plans to use hundreds of workstations at night and on weekends in addition to the compute servers. GRD has the potential to keep the necessary administrative efforts low since the simulation jobs must consider the individual workstation hardware and software (memory, CPU, operating system) and GRD accommodates these requirements.
The Army Research Lab (ARL) has developed a state-of-the-art Major Shared Resource Center (MSRC). It is now in full production, providing leading HPC technologies and tools to aid DoD scientists and engineers, according to Charles J. Nietubicz, Director of the ARL MSRC and Chief of ARL's High Performance Computing Division.
Of the four major centers in the DoD High Performance Computing DoD modernization program, ARL MSRC is the primary provider of multi-architecture classified systems. A full complement of unclassified HPC systems, as well as state-of-the-art near-line mass storage, and leading edge scientific visualization.
Recently ARL MSRC took delivery of two Cray T916, each configured with 8 processors and 512 Megawords (4Gb.) of memory. The addition of the most powerful parallel vector processing available to DoD augments the SGI distributed shared memory Origin 2000s, SGI/Cray J932s, and SGI Power Challenge Array serving defense scientists and engineers using the center.
GRD, as a new queuing system that dynamically allocates resources to the users according to preset 'sharing' guidelines and allows control of resources from a single point, is in use at the ARL MSRC since 1997. It dynamically adjusts available resources based on a share tree structure and the jobs currently running.
The system is a first for MSRC in that it controls all machines from a single queuing environment. ARL considers this as being "[...] a very good first step towards area-wide queuing for the MSRCs" according to Denice Brown, Manager of Operations and Customer Services at the Center.
At ARL, all users submit their jobs from a single interface no matter what machine the job is going to. In the present share tree structure, 20% of system resources are allocated to the DoD Challenge projects. The remaining 80% is allocated as follows: Army (30%), Navy (30%), Air Force (30%) and other DoD agencies (10%). This is in contrast to most traditional systems, which run jobs according to an assigned priority and size, and which cannot be adjusted once they begin execution.
Approximately 500 engineers, researchers and developers directly from ARL and other locations use the GRD system. Typically, user submit sequential as well as parallel jobs, the latter mainly using the Message Passing Interface (MPI) standard.
Under the GRD system, users specify information about the type of job they want to run. The system will automatically assign the job to the appropriate queue based on available resources and the job originator's position in the tree. Other parameters such as other jobs currently running for the same user are also factoring in, so that no one user can monopolize system resources. However, if necessary, the system administrator can override the automatic structure.
In addition, some applications such as certain periodic weather forecasts have increased priority as compared to other work, even though the departments or projects to which they belong may have little actual resource share.
Therefore, ARL´s resource utilization policy requirements can be summarized as:
In more than a year of operation GRD has successfully implemented ARL´s aforementioned operational goals as can be seen from the quote contained in figure 6.
In the future, ARL is looking into the direction of even more sophisticated share distribution schemes, wider usage of distributed memory applications in the GRD context and area-wide queuing activities.

The two sample customers scenarios of BMW and ARL as well as the technical description in the first section of this paper documented that GRD is a novel resource management system product with outstanding features targeted for HPC centers, enterprise or large department computing facilities as well as application or computing service providers.
As opposed to traditional queuing systems it has several unique capabilities, such as automated implementation of resource utilization policies across an enterprise computing environment combined with support for heterogeneous environments and flexible administration.
GRD helps site managers to gain overview on the resource utilization profile of an enterprise, to distribute resources fairly and to implement level-of-service agreements.
[ARL97] link, The ARL MSRC Newsletter, Volume 1, Issue 1, Fall 1997.
[BAKE95] Mark Baker, Geoffrey Fox, and Hon Yau, Cluster Computing Review, Technical report CRPC-TR95623 of the Center for Research on Parallel Computation, Rice University, November, 1995, 70 pages.
[CASA96] Christine Casatelli, Managing in the Distributed World, RS/Magazine, April 1996, Vol. 5, No. 4, pp 30-38.
[COD197] CODINE Installation and Administration Guide, Version 4.1, 143 pages., 1997.
[COD297] CODINE User's Guide, Version 4.1, 81 pages., 1997.
[FISC95] Craig Fischberg et. al., Using Hundreds of Workstations for Production Running of Parallel CFD Applications, Proceedings of Parallel CFD '95, Elsevier Science Publishers B.V., The Netherlands, 1995, 14 pages.
[GEN98] README!, GENIAS bi-monthly newsletter, June 1998.
[GILL96] Philip J. Gill, Integration Alters Systems Management Mix, Software Magazine, Jan 1996, pp. 65-71.
[GRD197] GRD Release Notes & Installation Guide, Version 1.1, 103 pages, May 1997.
[GRD297] GRD User´s Guide, Version 1.1, 111 pages, May 1997.
[IEEE94] IEEE Standard 1003.2d-1994, Portable Operating Systems Interface (POSIX®) Part 2: Shell and Utilities, Amendment 1: Batch Environment.
[JON97] Jones, J. P., Brickell, C., Second Evaluation of Job Queuing/Scheduling Software, NASA Ames Research Center, U.S.A., NAS-97-013, June 1997.
[KAPL94] Joseph A. Kaplan, Michael L. Nelson, NASA Langley Research Center Report #109025, June, 1994, 48 pages.
[KAY88] J. Kay and P. Lauder, A Fair Share Scheduler, Communications of the ACM, January 1988, Vol 31, No 1, pp 44-55.
[ROCH96] Larry Roche, Henry Newman, Johannes Grawe, Operational Needs for Software Products That Manage Batch Workloads and Distributed Computers, Proceedings of Computer Measurement Group, CMG 96, San Diego, CA.
[WALD94] Carl A. Waldspurger and William, E. Weihl, Lottery Scheduling: Flexible Proportional-Share Resource Management, Proceedings of the First Symposium on Operating System Design and Implementation, November 1994, 11 pages.