|
|
|
|
Chuck Keagle
Super-computing Performance Analyst
Engineering Systems Support
The Boeing Company
P.O. Box 3707 MC 7J-04
Seattle, WA 98124-2207
The Cray T916-512 compute server in our Bellevue Data Center has been overloaded for several years. It seemed that every time we upgraded the hardware the User Load Immediately expanded to consume it. Sometimes, it even expanded in anticipation of it. When looking at the application mix on the triton, we noted that many codes were either scalar or not well vectorized. This led us to look at providing more scalar compute power by installing a high end scalar processor to take some of the scalar and short vector length dominated codes. This would ease the load on the triton.
We looked at the IBM SP, HP Exemplar S Class, and SGI/Cray Origin 2000. System performance was important (See Appendix A for timing studies) but so was the learning curve for our support staff, development staff, and end users. The Origin not only fit our requirements better than the other two, its product line was to eventually replace the triton (the SN-2V).
Our next task was to integrate this new technology into our Data Center. We focused on support issues in order to provide a service to our users that we felt would be reliable and to which they could easily migrate. We wanted to use as many of our Unicos administrative policies and procedures as we could in order to ease the migration for us. With this in mind, we set about installing and configuring our new Origin2000. With each integration task, we wanted to satisfy the following requirements:
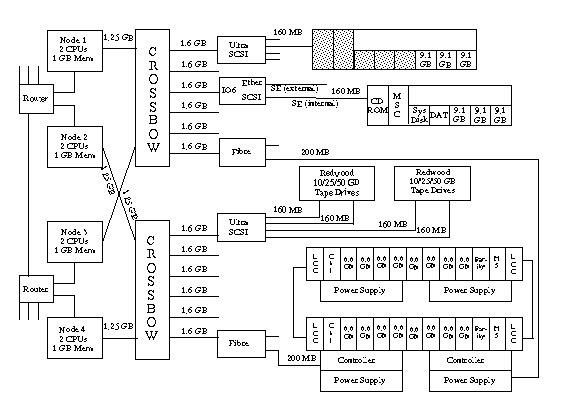
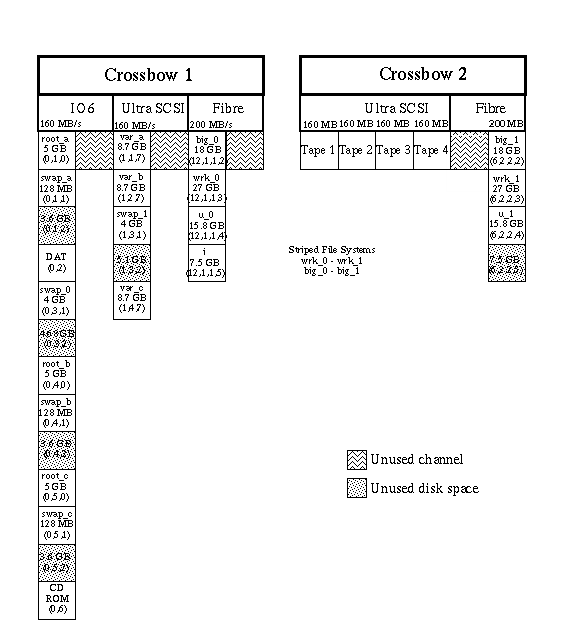
We purchased a four node Origin2000 with two Ultra SCSI controllers (in addition to the IO6 SCSI bus) and two Fibre Channel controllers. Each SCSI controller provides four 160 MB channels. Each Fibre Channel controller provides two 200 MB channels. We put one SCSI controller and one Fibre Channel controller on separate 1.6 GB channels on each Crossbow in order to minimize contention for the available bandwidth of 1.25 GB from each node to it's associated Crossbow. This worked out very well for our two 70.4 GB Fibre RAID Disk Arrays which are dual ported. The data transfers to and from the Fibre RAID Disk Arrays is evenly divided between the two Controllers (and Crossbows).
We have four 50 GB Silo Attached Redwood Tape Drives that we use for user data backups and for the Data Migration Facility (DMF). Each of these is dedicated to a SCSI channel, and all four fully populate the four channels of one Ultra SCSI controller. Without a Tape Management Facility (TMF), the Origin must rely on our Hierarchical Storage Management (HSM) server Automated Cartridge System Library Server (ACSLS) to load and unload the tape drives and manage the tape pool. We also must dedicate tape drives to certain functions until the TMF is available. One drive is dedicated to write the DMF primary copy, one for the secondary copy, and one for user file backups. This leaves one tape drive for use as a backup device for the other three.
We have seven 9 GB SCSI disk drives dedicated to system and support roles. Three of these are for various versions of the root file system (root_a, root_b, and root_c) and swap (swap_a, swap_b, and swap_c). Another three are for the /var file systems (var_a, var_b, and var_c) associated with their respective root file systems. More information about these file systems is available in the System Level File Systems section. Finally, part of one SCSI disk is used for the DMF database. Figure 1 shows our Hardware Configuration.
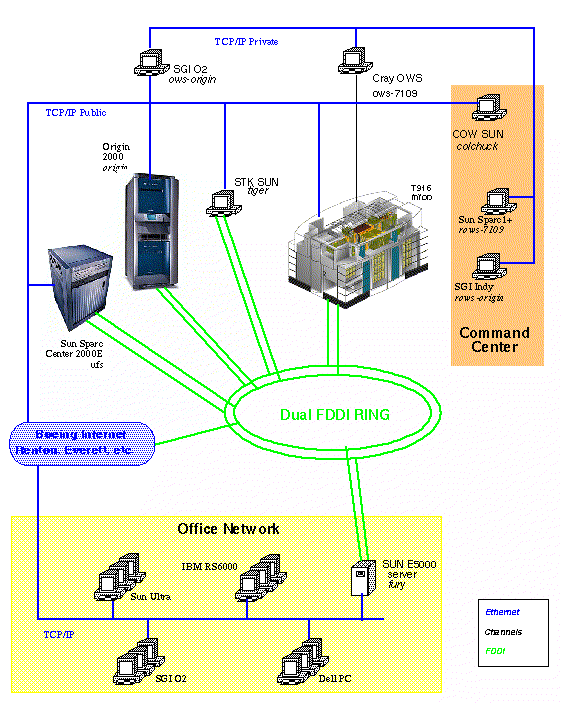
In order to integrate the Origin2000 into our Data Center Environment, we provided a Dual FDDI Ring interface for access to our HSM System called Unix File Service (ufs) and a back-up 100-BaseT Ethernet interface (they are 10-BaseT) to provide access in the event of a FDDI Ring failure. Neither the Cray nor the HSM system have 100-BaseT Ethernet Interfaces so the 100-BaseT service provides the potential for increased reliability for the Origin2000. Both the Dual FDDI Ring and the 100-BaseT Ethernet have Fibre interfaces directly to the Corporate Backbone Network. In this way there is no single point of failure between the origin and the Boeing Internet. Figure 2 shows our network configuration.
Our Consolidated Operator's Workstation (COW) monitors network accessibility to the UFS, Triton, and Origin every 60 seconds. It sends a ping to each host at 200 msec intervals for two seconds. If it receives a reply to any of the 12 pings to a specific host it considers that host accessible. If none of the pings are answered, the COW issues both audible and visual alarms for operator response. It is then the operator's responsibility to determine whether the problem is network or host related and summon the appropriate support personnel for problem resolution.
As always, Configuration Control turned out to be a two edged sword. The Unicos development staff was comfortable with USM and did not care much for either SCCS or RCS. However, USM is not available on IRIX and RCS and SCCS are. USM provides line number control to build mod-sets that can be applied to current and future systems. The context diff and patch mechanism to maintain source code control using either SCCS or RCS require re-integration with each new release of the Operating System. Since the source for IRIX has not yet been released, and we do not yet know what form it will take, we chose to maintain our local tools and system scripts modifications on Unicos in USM format for several reasons:
Patch Sets are released by SGI/Cray monthly. We provide a production service to our users that we have thoroughly tested and have a strict Q/A cycle to accomplish this. We maintain a high degree of reliability in the services we provide, and we decided that we could not Q/A Patch Sets on a monthly cycle without increasing the staffing level in our Q/A group. We chose a bi-monthly cycle which will keep the system up to date to within at most one patch set behind.
Our Q/A cycle consists of building a test system on an alternate disk by making new root and var File Systems, copying the production system, and applying new Patch Sets and local modifications. This activity is accomplished while the production system is running. To test the new system, four hour time slots are blocked out on Wednesday and Saturday evenings to take the system down for dedicated testing. Once testing is complete, the root, SystemPartition, OSLoadPartition, and kernname Prom Environment Variables are modified to automatically boot from the new disk partition and the new production system is established. The old production system is then kept intact for a period of one week in the event that a problem develops with the new system and we have to fall back to the old. If we experience a problem that causes our users to lose time out of their schedules, we have developed an emergency patch installation process to insure that our user's productivity is not negatively impacted until the next system is put into production. We have developed a sysedit utility that helps us to insure that only one user modifies the production system at a time for installation of these emergency fixes. The sysedit utility asks some questions to create an Audit Trail Entry of the change, checks the username to insure it is one of our trusted System Support Staff, and then makes both the effective and real UIDs root so the change can be implemented.
Each system is described by the output of the showprods program. Boeing has a unique requirement to be able to reproduce the environment an aircraft was designed in for as long as is practical. This practicality usually ends when we can't get the hardware our old systems ran on anymore. But until that time, we want to be able to reproduce the system at the same release level and patch configuration the design data was created under.
In this area, we had to overcome a few incompatibilities. Unicos uses the User Data Base (UDB). The UDB is to be ported to IRIX, but is currently still vapor-ware. What we had, though, was a tool to maintain users on several of our Enterprise Server Systems which we easily extended to include the Origin. Our home grown Account Management System (AMS) has been with us for many years and our Account Management staff needed no extra training in order to incorporate the Origin2000 into the pool of hosts the AMS controls. The AMS insures User ID (UID) commonality across all hosts it controls. This is important for NFS mounted file systems. It allows our User Support Staff to add or delete user accounts, and modify any field in the /etc/passwd or /etc/shadow files using addUserAccount(1M), modifyUserAccount(1M), and deleteUserAccount(1M).
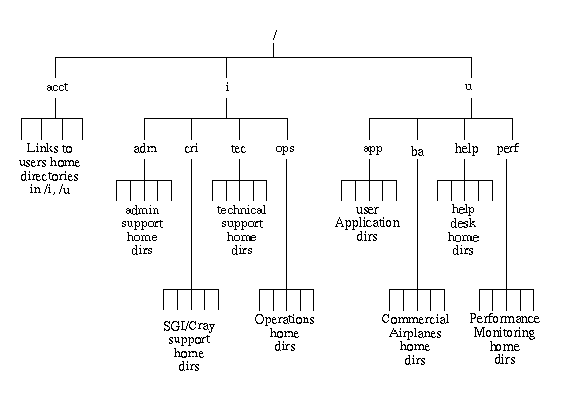
In defining a user directory structure, we already had company wide guidelines to follow. We had not followed these guidelines when we built our Unicos user directory structure since they didn't exist at that time so this was a good chance for us to bring about some harmony between our server system and the client workstations our users work from. We implemented the Boeing Common Directory Structure (CDS) that has been a standard in the Boeing Commercial Airplanes Division for several years now. Within the CDS is a directory of links to the various file systems that contain our user's home directories. See Figure 3. This directory, /acct, is then entered into the Home Directory field in the /etc/passwd file so all users on the system are referenced as /acct/username regardless of where their home directories physically reside.
We have a requirement to allow all boeing employees access across all Boeing user directories and to dis-allow access to all Boeing home directories to non-boeing employees that have no need for access (i.e. A Boeing employee can at least see the top level directory for all other Boeing Employees but a non-Boeing employee can only see those home directories necessary to accomplish the task). We satisfy this requirement by defining group Boeing in the /etc/group file and adding all Boeing employees to the group. On Unicos, we then turn off all permissions for others and turn on read and execute for group. This works. On IRIX, there is a bug in login somewhere that requires other execute permission to a user's home directory in order for the $HOME/.rhosts file to be visible for user validation. These permissions (0750 on Unicos and 0751 on IRIX) are set on all directories in the paths to all User Home Directories.
User Home Directories are separated at the top level by function. The /i directory is used for Data Center internal support staff accounts. The /u directory is used for production user accounts. Below the functional separations are job duty directories. The /i/tec directory is used for Data Center internal technical support accounts. The /u/ba directory is used for Boeing Commercial Airplanes Division accounts. In order to balance the disk usage demand we have separated the /u directory into /u, /u1, /u2, and /u3 on UNICOS. We continually monitor disk utilization and try to make adjustments only when we see major bottlenecks that affect system performance. A typical adjustment to balance the user load would be to create a new user file system and move some users to the new file system such that there is some balance in the amount of space consumed by the users in all user file systems. This balance is tempered by our experiences with each user's peak demands on I/O resources.
Our Operations Staff is located about 500 feet from the Origin. To allow them to operate the Origin from this distance, we installed IRISconsole on an O2 located next to the origin (suitably named ows-origin) to act as the console. This O2 has two Ethernet interfaces; one to the Fast Ethernet the Origin is connected to and one to the private Network our Cray OWS and MWS are on. Since this is a private network and the Cray OWS and MWS are critical to the operation of the Cray, we have turned off ipforwarding on ows-origin to provide an extra level of security for that network. IRISconsole is built on The X Window System, so we can easily display its windows anywhere. We installed an Indy in the Command Center and put it on the same network the Cray OWS, MWS, and Remote OWS are on. This gives the Operations staff full command and control capability over the Origin. In this way, the operators can run IRISconsole on the O2 and use their Indy as the X server.
An added feature of the IRISconsole is it's versatility. Any member of our support staff with a DGL equipped SGI system can steal the console away from the Operators (after coordinating with them of course) if needed in order to diagnose problems the operators are not prepared to deal with. IRISconsole basically provides us the capability to provide sixteen different terminal interfaces from a single host. We have defined a second port on the IRISconsole to connect directly to the RS-232 interface on the RAID Array for diagnostic purposes.
Once the operations staff had the capability to command and control the Origin, it became my responsibility that they knew what to do. Our Operations Staff also runs the Cray, Teradata, IBMs (both MVS and AIX), and Cybers. IRIX was a new beast for them to tame, and their job was made artificially more difficult because they had to pass through an O2 with ipforwarding turned off to get to the Origin. The operator training process was completed in three phases.
At 8 PM Sunday Evening, perform a system reboot so a configuration change can take affect.
There are two phases to performance tuning. The first phase is to tune the system for the overall user load. Once the system is tuned, we dive down to the application level to help our users tune their applications to utilize the required resources more effectively. We have yet to start phase two so this paper will concentrate on phase one; Tuning The System For The Overall Load.
The Performance Co-Pilot (PCP) has proven to be a very useful tool to find where the system is performing poorly. We run the PCP Collector and Monitor on the origin and three copies of the visualization software on the O2s on our Office Network. Our performance specialists have an O2 dedicated to visualizing various performance metrics. This host also runs three different pmloggers that each focus on different metrics:
PCP 1.x does not support multiple pmloggers, but we found that we could define different DNS domains in the /etc/hosts file for the origin and assign each pmlogger to a different domain. This worked very well for us. We added origin.webdata, origin.detail, and origin.disk entries for the origin host and the three pmloggers were content. When we upgraded PCP to version 2.0, we found that this method was exploiting a hole that version 2.0 had closed. However, PCP 2.0 supports multiple pmloggers by defining them in the /var/pcp/config/pmlogger/control file.
We use PCP to get an idea of the instantaneous loads on the system using dkvis, mpvis, and oview. Our performance specialists have these displays up continuously on their O2. For historical data, though, we still use sar. We have a number of Web based visualization tools built on sar that were easy to extend to the origin. These tools automatically update resource utilization Web pages every ten minutes. We can also obtain data over any time interval on demand. As an example, note the high level of %wio in Figure 4 and the high percentage of %wio consumed by %wfs in Figure 5.
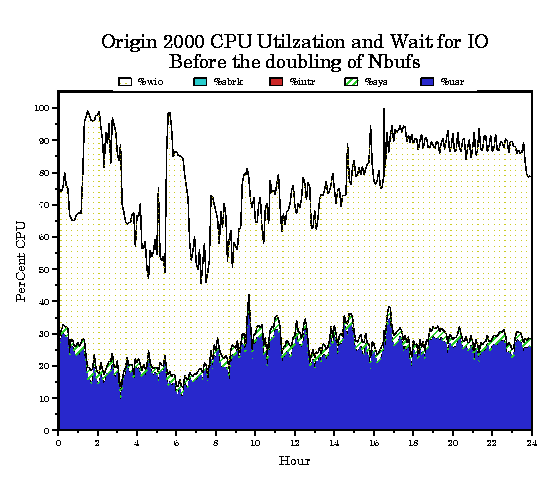
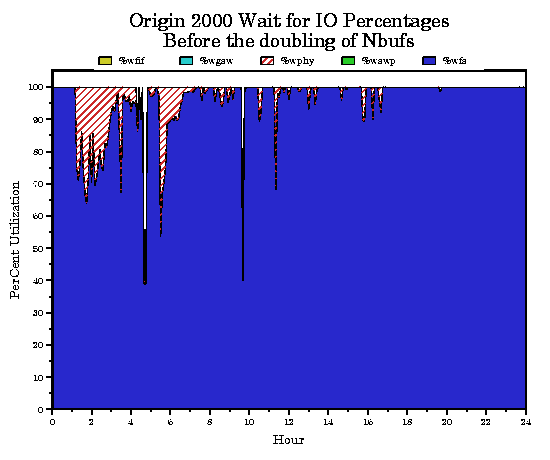
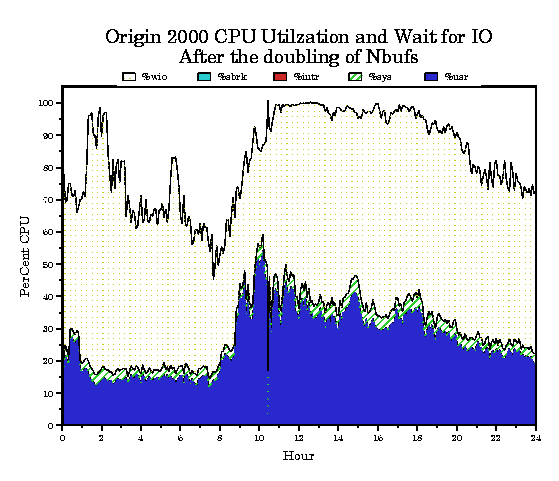
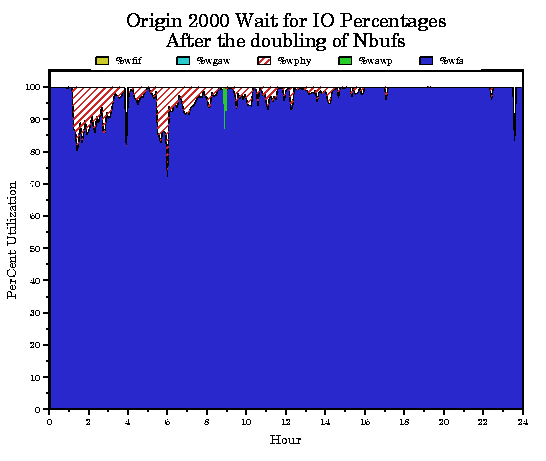
After noting this we decided to double the value of nbuf which doubled the size of the buffer cache. After the change note that %wio still dominates the total CPU time in Figure 6, but now the %wphy appears to have increased slightly as a percentage of %wio as shown in Figure 7. This led us to the conclusion that the system needs more disk channel bandwidth. This made our Sales Rep happy.
We also wanted to set some interactive limits that would encourage the users to use the batch queues. We felt that 30 minutes of CPU time was plenty for any interactive session. We also felt that double the size of physical memory was plenty for the virtual size of any interactive session. We set the following systune parameters as indicated:
rlimit_core_max = 0x1f4000000 LL (8 GB)
rlimit_core_max = 0x1f4000000 LL (8 GB)
rlimit_cpu_cur = 1800 LL (30 mins)
rlimit_cpu_max = 1800 LL (30 mins)
Some jobs our users are running on this machine consume in excess of 100,000 CP seconds. Since NQE ignores these "interactive" limits, our users must use NQE in order to run these jobs. With these interactive limits set, we then went about setting up the NQE/NQS batch queue limits. Working with physical memory for so long on the Cray, these limits were hard for us to grasp. Some of our administrative staff had trouble making the leap from physical memory to virtual memory. We learned from other users, though, that over subscribing memory by more than about 1.25 times physical memory caused dramatic reductions in performance. We set up the following NQS queue structure matrix and created batch queues to support it.
|
|
|
Large CPU |
|
|
Small Memory |
Msm_Csm |
Msm_Cme |
Msm_Clg |
|
Medium Memory |
Mme_Csm |
Mme_Cme |
Mme_Clg |
|
Large Memory |
Mlg_Csm |
Mlg_Cme |
Mlg_Clg |
We also established a Queue Complex structure to limit the jobs in these batch queues. The complexes serve to insure that we do not over subscribe either the CPU or memory. The Queue Complex structure sets a Run Limit of 3 on all large memory jobs, 8 on all medium and large memory jobs, 7 for all large CPU jobs, and 9 for all medium and large CPU jobs
There are two levels to file system structure. First, we wanted system level file systems in place. Then, there were user level file systems we wanted in place.
We wanted to define three root file systems. The production system, a backup system, and a test system. This required at least three disks. Each disk has a 5 GB root file system and a 128 MB swap partition. We determined from SGI that 128 MB was enough room to hold the interesting information in a memory dump on our 4 GB system. There are 3+ GB of unused space on each of these disks for future expansion.
In order to increase the swap space to something more reasonable for production, we defined two 4 GB raw partitions on each of two Ultra SCSI channels and configured them as additional swap space. The /etc/fstab entries to accomplish this are as follows:
/dev/dsk/dks0d3s1 /swap swap 0 0
/dev/dsk/dks1d3s1 /swap swap 0 0
We wanted to define a separate /var file system so log files that grew very large would not fill up the root file system and cause the system to crash. This implied a separate /var file system for each root file system. To decrease disk contention, we defined each pair of root and swap file systems on one SCSI channel and the /var file system on a another SCSI channel. See Figure 8 for a graphical description of our file system layout.
NQS uses /tmp for it's $TMPDIR working storage on the Origin2000. On our Unicos system, $TMPDIR is defined in /wrk. In order to duplicate this structure we defined a /wrk file system with tmp and var/tmp sub-directories. We also defined /wrk/tmp and /wrk/var/tmp in the root file system and created symbolic links to point /tmp to /wrk/tmp and /var/tmp to /wrk/var/tmp. In this way /tmp, /usr/tmp, and /var/tmp are defined regardless of whether /wrk is mounted. During normal operations, NQS uses /wrk/tmp for $TMPDIR. If we are in Single User Mode and want to run a program that uses /tmp for scratch files, we can because /wrk is defined in the root file system even when the /wrk file system is not mounted.
Our users are also used to having a $TMPDIR defined for them when they run interactively on the T916. This was difficult to set up on IRIX since we have no source for the login program. Under Unicos we modified login to create TMPDIR as /wrk/jtmp.uniqueNumber.a at login and then to delete it at log out. Under IRIX, we modified /etc/profile and /etc/cshrc to create directory /wrk/jtmp.sessionNumber and define TMPDIR to point to it. We placed the following code into the /etc/profile file in the section that is executed only for first time logins:
# Create user's TMPDIR in /wrk if TMPDIR is not defined. # For NQS jobs it will be defined which is good because # "ps -j" does not work when no terminal is assigned. if [ -d /wrk -a -z "$TMPDIR" ] then sessid=`/sbin/ps -j | /usr/bin/awk '{if ( NR == 2 ) print $3}'` export TMPDIR=/wrk/jtmp.$sessid unset sessid if [ ! -d $TMPDIR ] then /sbin/mkdir $TMPDIR /sbin/chmod 700 $TMPDIR fi fi
We also did this in /etc/cshrc using the appropriate syntax. This was the easy part. There was nothing we controlled under IRIX that we could use to clean up on logout. The $HOME/.logout file can not be controlled by root so we had to come up with another mechanism. By embedding the session ID in the file name we were able to write a script that looks for files in /wrk with names jtmp.sessionID. The script then extracts the sessionID from the file name and looks for jobs with the session ID. If it doesn't find any, it deletes the directory out of /wrk. This script is then run out of cron every 15 minutes. When we obtain the source to IRIX, we will be able to implement this feature similarly to the way it is currently implemented on Unicos.
#! /bin/sh # USMID @(#)cnfgcntrl/cleanwrk.sh 1.2 12/12/97 13:11:11 # Script to clean the /wrk directory periodically. # All directories in /wrk are checked to see if there is still # a session using them. If a directory is not associated with an # active session, it and all its contents are deleted. cd /wrk if [ "`ls | grep jtmp`" != "" ] then for name in jtmp.* do sessid=`expr $name : '.*\.\([0-9]*\)' \| $name` if [ "$sessid" = 'jtmp.' ] then # sessid should be a number, but if it is # 'jtmp.', then /etc/profile or /etc/cshrc # created '/wrk/jtmp.' because is could not # obtain a session id. continue fi if [ `ps -s $sessid | wc -l` -eq 1 ] then rm -rf $name fi done fi
The structure of a file system directory entry can affect file system performance. DMF uses the Data Migration Application Programming Interface (DMAPI) in accessing the XFS File Systems. In order to maintain good performance in DMF we increased the size of the inodes in those file systems under DMF control. This must be accomplished when the file systems are built as follows:
mkfs_xfs -i size=512 /dev/rdsk/dks0d7s7
mkfs_xfs -i size=512 /dev/rxlv/wrk
On our Cray we have defined two file system structures for each user. Their home directory structure is as defined in the User Maintenance Section. We also have a /big file system whose structure is identical to that of the home directory file systems but with a /big prefix. If user1's home directory is /acct/user1, there is also a /big/acct/user1 directory for this user. In this way $HOME refers to /acct/user1 and /big$HOME refers to /big/acct/user1. The /big file system is optimized for files that are larger than 300 MB in size. It is striped across two physical volumes with a stripe size of 512. The Health Monitor looks for large files in /acct. When it finds one, it moves it to /big and creates a symbolic link to the new location from the /acct sub-directory. This structure has been duplicated on the Origin2000.
The Boeing Common Directory Structure defines a standardized execution environment for our users that they have grown very accustomed to. It consists of a binary directory that is added to the user's path, a library directory for compiling, an include directory for compiling, a man page directory that is added to the user's MANPATH environment variable, and a software directory to maintain multiple versions of the same program. This directory structure is designed to be used as an execution environment. Separate directory structures are used for development. The only source code in the CDS is that contained in the include files.
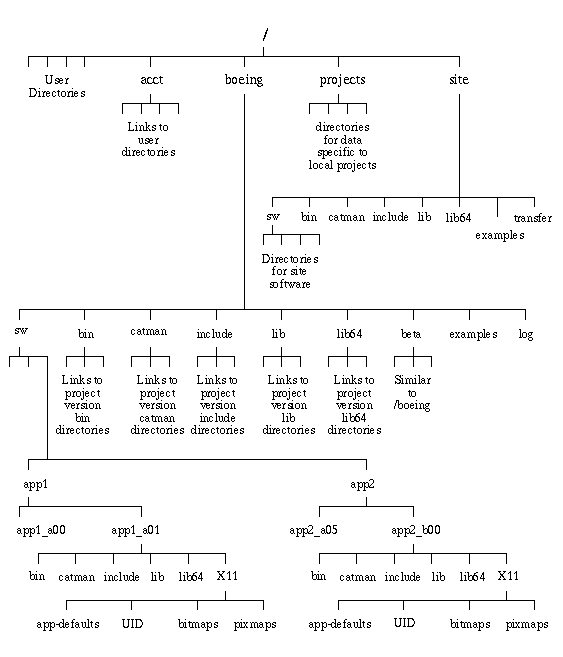
The CDS defines separate directory structures for Boeing application software, 3rd party code, and site local software. The Boeing application software is controlled and archived by a group whose sole purpose is to insure that all Boeing written code adheres to Boeing standards. This directory is under the complete control of the site Administrative staff. The 3rd party software is software that has been purchased for specialized purposes at a site, and is also controlled either by the Administrative staff or by an application focal. The site local software is controlled only by the site and is typically open for group writing by the sites development staff. See Figure 9 for a description of the CDS execution environment.
The T916 is performs very well on vector dominated codes with long vector lengths. It's scalar and short vector length performance drops off quite dramatically. Appendix A shows that ABAQUS can perform better for some cases on the Origin than on the T916. This code is a good candidate to offload from the triton to the origin. Another good candidate is ANSYS. However, CPU performance is only one piece of the pie. ABAQUS and ANSYS are both heavy I/O codes and the value of the SSD to speed up I/O can not be overlooked. The origin must be tuned for heavy I/O and the bandwidth from memory to disk must be adequate for these codes to run without causing the machine to become I/O bound.
A good mix of CPU burners and I/O hogs works very well on the origin. While the I/O hogs are waiting for I/O to complete, the CPU burners keep the CPUs from becoming idle. We have just started testing a tlns3d code on the origin that does just this. While the ABAQUS and ANSYS CPUs are waiting for buffer cache, tlns3d keeps the CPUs humming along with very little crosstalk between the routers. Initially, the tlns3d jobs have been small, so this behavior may cause the machine to become CPU bound as it is scaled up.
Looking back over the project, we learned (sometimes relearned) a number of lessons that are worth sharing. Many of these grew from our past experiences with Unicos and problems we have solved on that system that also applied to this system.
PCP 2.0 supports multiple pmloggers and this kludge must be withdrawn so pmlogger will work properly.
origin.web n n /var/adm/pcplog/origin.web -c config.origin.web
origin.data n n /var/adm/pcplog/origin.data -c config.origin.data
origin.disk n n /var/adm/pcplog/origin.disk -c config.origin.disk
Now that the Origin is in a production state in our Data Center, we have some ideas for new functionality we would like to add to make our support jobs easier.
We tested two data cases on the T916, Origin2000, and HP Exemplar S Class. Both cases related to the 757 Flap Skew analysis currently being run on the T916. As the trailing edge flaps are extended, high forces can cause one or more of the tracks to bind causing the flap to skew. The Flap Skew Analysis insures that the aircraft will remain stable in this configuration. Both cases were run under ABAQUS 5.6-4. The tests were run at multiple increments shown as INC=50 and INC=200. The results tabulated in Table 2 indicate that both the Origin2000 and the Exemplar outperformed the Triton when comparing both Total CPU Time and Wall Clock Time. This is the bottom line for our Engineers.
|
CPU |
T916 |
Origin2000 |
HP |
T916 |
Origin2000 |
HP |
|
User (Test 1) |
3168 |
2683 |
2642 |
12961 |
10795 |
11293 |
|
System (Test 1) |
142 |
265 |
16 |
292 |
1117 |
92 |
|
Total (Test 1) |
3209 |
2948 |
2658 |
13253 |
11912 |
11385 |
|
Wall (Test 1) |
8687 |
2975 |
3061 |
25300 |
13129 |
17563 |
|
User (Test 2) |
3460 |
1899 |
2310 |
13973 |
7733 |
8755 |
|
System (Test 2) |
58 |
209 |
8 |
378 |
894 |
42 |
|
Total (Test 2) |
3518 |
2108 |
2318 |
14351 |
8627 |
8797 |
|
Wall (Test 2) |
4726 |
2338 |
2555 |
27267 |
9653 |
15690 |
| Chuck Keagle is the Program Manager and System Administrator for the Origin 2000 Integration into the Boeing Data Center. He also serves as the System Administrator for the SGI hosts used by various staff members in support of the Origin 2000. Other duties include providing Cray T90 Application Level performance optimization support to the Boeing User Community by finding poorly performing applications and helping the developers to profile and modify their codes to improve their performance on the Cray T90 series machines. |
 |
![]()
