|
|

Link to slides used for this paper as presented at the conference. They are in Acrobat PDF format.
|
|
![]()
Ken McDonell
Performance of large and complex computer systems is sensitive to a daunting number of parameters and policies. In this environment performance monitoring and performance management is a challenging task, but one with huge potential rewards given the capital asset investment and the strategic value of the applications these systems support.
In this context "performance" usually means the rate at which work is completed (job or task throughput) subject to quality of service constraints (often expressed in terms of elapsed time and/or response time criteria).
Independent of the definition, performance optimization involves:
In this paper we are concerned with system-level performance, particularly in the context of large and complex machine configurations.
Monitoring and managing the performance of a large system is a challenging task, particularly as a consequence of:
Consider a system with the following general characteristics:
Given normal sar-like instrumentation from the operating system, a sample period of 20 seconds, and ignoring the process-specific data, then the raw performance data grows at a peak rate of about 3000 bytes per second or 12 Mbytes per day.
The best performance analysts (of the humanoid variety) can process ASCII data at the rate of approximately 150 bytes per second (a screenful, or 1500 bytes, about every 10 seconds). It is clear that the traditional representations of sar, *stat, et al are woefully inadequate for comprehensive performance monitoring of these systems.
For IRIX, the information reported by sar is merely the tip of the iceberg, and the total amount of system-level performance data that could be collected on one of these systems is astronomical. Ignoring multiple values for metrics defined per CPU or per disk, the sar collection is about 100 performance metrics while the PCP agent for IRIX exports close to 800 performance metrics.
When one includes process-specific data, tools like ps are effectively useless (the output for 10,000 process is 45 pages long when printed 4-up in 6 point typeface) and if you are using top then it is most likely that you are the performance problem!
Solving difficult performance problems in complex systems often requires access to very low-level information and/or high frequency sampling, e.g. event traces or run-time profiles of individual library calls or time stamping of the stages in the processing of a disk request or a log of latencies through the maze of protocol layers for a single network packet. While some of the most critical performance problems cannot be solved without this detailed performance data, the burden of collecting this information is so large that we cannot afford to collect all of the information all of the time. As a related issue, some of this detailed information is only available in versions of the software created under certain magic spells, hence the "special" version to help identify a performance problem (note that to actually solve the problem typically requires a different magic spell).
Monitoring, understanding and managing performance is an activity that tracks the product life-cycle. Each of the following stages in a product's evolution demand some form of assistance for system-level performance analysis.
Despite the common interest in system-level performance, each of these functions imposes different and sometimes conflicting requirements upon the infrastructures for collecting performance information and the tools that process that information. One of the challenges is to support these diverse needs with an architecture and implementation that is both flexible and efficient.
Like Chicken Man, "it's everywhere, it's everywhere, ..."!
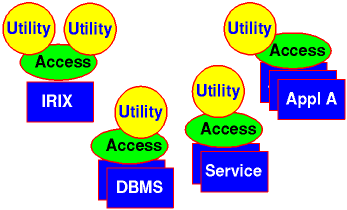
Specifically, there is performance data maintained in the hardware, the operating system kernel, the service layers, the application libraries and the end-user applications. The situation is generally as shown in Figure 1, with a number of independent domains, each with its own collection of performance metrics and associated infrastructure for exporting and displaying information about performance.
In general this arrangement makes it difficult to find, much less correlate all of the relevant performance data for a particular performance analysis task. But even if you can negotiate the twisty passages to find the raw data, the semantics of the data (what it is we are counting, measurement units, format of a counter, how often it is updated, etc.) remains a secret. Another frustration is that knowledge accumulated for the current release may not be helpful for the next release when the access methods and data semantics may change.
Clearly we need an abstraction that supports the following services:
If we had this unified interface to the performance metrics then we'd be in a position to build some interesting performance tools that would work for all performance metrics.
Performance Co-Pilot (PCP) is a family of products from Silicon Graphics that deliver system-level performance monitoring and management services. PCP is designed for both operational monitoring (tactical performance management) and the in-depth analysis that is needed to understand and manage the hardest performance problems in our most complex systems (strategic performance management).
An more detailed description of the PCP product may be found at http://www.sgi.com/software/co-pilot/features.html.
PCP is a released product for all Silicon Graphics platforms running IRIX 5.3, 6.2, 6.3, 6.4 or 6.5.
Humans cannot fly large and complex aircraft without the assistance of computer-based avionics. The same is true of large and complex computer systems (e.g. servers for DBMS, file, compute, Web and media).
The breadth and depth of the available, and potentially useful, performance information is daunting. The protocols to transport this information, the tools for processing the information and the user interfaces for presenting the information must be scalable and usable for the largest configurations.
Dealing effectively with the dynamic behavior of complex systems requires services that automate the mundane management tasks and filter the "noise" from the overwhelming stream of performance data, allowing the human to concentrate on the exceptional and the unusual. When this is done, the user can concentrate upon in-depth analysis, or target management procedures for the critical system performance problems.
As in engineering, science and data mining, the power of 3-D visualization enhances the performance analyst's capacity to extract insight and understanding from large and complex data sets.
Performance Co-Pilot tools provide scalable visualizations of performance, "drill down" investigation, flexible logging for retrospective analysis and automated reasoning about performance data to provide the necessary high-bandwidth filtering and assistance in understanding.
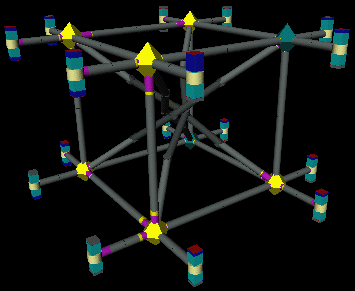
Consider a hypothetical large Origin 2000 for which performance of the mission-critical applications is sensitive to total CPU utilization and traffic within the CrayLink interconnect fabric that supports the ccNUMA memory model. Figure 2 shows a visualization for a 32 processor system with 8 routers, 32 CrayLink connections (both router-router and router-hub connections) and 8 "express" CrayLink connections. This scene is constructed by the PCP tool oview and includes graphical objects to represent the transmit data bandwidth on each bidirectional CrayLink connection, the average utilization of each router and the user and system CPU time for each processor. oview uses performance data to animate both the color and the size of the objects in the scene; both real-time and retrospective (replay) visualization is supported. The visual model is constructed dynamically for each system based on the interconnect topology and hardware inventory exported from the PCP data collection infrastructure.
Figure 3 shows a different visualization paradigm that uses spatial proximity and color to highlight related disks on the same controller and height modulation to show spindle-level disk activity (an object's height is proportional to the I/O rate of the associated disk). Note that even with some 650 objects in this scene of a Terabyte disk farm it is immediately obvious which disks are idle. This tool (dkvis) automatically adapts to the shape and size of the disk configuration on any system and can be used to graphically monitor the load balance or shifting patterns of use over time or correlation between peaks of I/O bandwidth demand and other system activity.

For many systems, the rate at which performance data is being produced requires some sort of intelligent filtering to automate the process by which the mundane data can be removed from the interesting information.
Once interesting information has been found, there are a variety of actions that may be appropriate.
The PCP inference engine enables automated filtering and intelligent processing for very large amounts of performance data by evaluating a set of assertions against a time-series of performance data collected in real-time from one or more hosts or from one or more PCP archives. For those assertions that are found to be true, customized actions cause a warning to be posted (e.g. print messages, send e-mail, activate visible alarms, write syslog entries, etc.) or an arbitrary program to be launched (e.g. activate a pager, change a tuning parameter or cause some aspect of the system's configuration to be adjusted).
Example: concurrently monitor Web server response time from different locations and resource utilization at the Web server host, so that problems can be automatically classified and passed to the platform operations staff (for Web server performance problems) or the network operations center (for apparent network performance problems).
Typical use of automated reasoning about system-level performance might include:
Often performance analysis is expedited when it is possible to compare today's end-user performance, activity levels and resource utilization against the same information from yesterday, last week or last month. This form of retrospective playback is most useful in problem analysis, hypothesis evaluation, remote diagnosis and capacity planning.
The PCP archive logging services are powerful and flexible and may be configured to collect the necessary information with a user-defined coverage (in terms of the scope and level of detail of the desired performance metrics) and frequency. The profile of performance data being logged can be changed dynamically. Archive logs may be accumulated either at the host being monitored.
Example: The inference engine and the archive logging tools can co-operate to provide adaptive logging where the breath and depth of the performance data in the archive logs is adjusted dynamically so that when a problem first appears the necessary data will be added to the archives and/or the logging frequency adjusted to support detailed retrospective analysis. When the inference engine detects that the problem is no longer present, or after some time has elapsed the logging setup reverts to the default configuration.
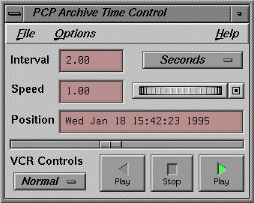
A universal replay mechanism (modeled on a VCR paradigm, see Figure 4) is used by most PCP tools to provide "stop, seek, rewind, and replay at variable speed" processing of historical performance data.
The requirement for uniformity also leads to the Performance Co-Pilot view that real-time and historical sources of performance data be viewed as interchangeable and semantically equivalent.
A set of scripts and control files combine to provide integrated management of the process of collecting PCP archives, including automatic starting and monitoring of the logger processes, daily log rotation, log culling, log merging and extraction, and flexible deployment of the logs and logging processes across multiple hosts.
For many end users of Performance Co-Pilot, the most important and useful performance metrics are not those supported by the shipped PCP product, but rather new performance metrics that characterize the essence of "good" or "bad" performance at their site, or within their application environment. Performance metrics such as transaction service times, rate of progress on solving a problem, operations completed, queue length of pending tasks, etc. are specific to a particular site or application, but need to be quantified and processed in the context of other performance measures relating to the environment in which the applications are running.
Example: Instrument a numerical application to measure progress in the stages of a computation. Use the PCP components to export this information to a monitoring station where a customized 3-D visualization shows application progress (iteration rate, error term convergence, number of subproblems solved, etc.), process-level resource utilization (CPU consumption, TLB misses, page faults, etc.) and concurrent platform activity (disk I/O, context switch rate and processor secondary cache miss rates).
PCP services are constructed from powerful building blocks with well-defined interfaces for customizing both the collection and the presentation of the performance data. The product provides libraries, source code examples, tools and debuggers that encourage the development and integration of new sources of performance metrics as peers into the collection infrastructure. In the simplest case, agent development involves no more than writing a single function in C to instantiate metric values on demand, with all communication, protocol handling and administrative services delegated to PCP libraries.
The guiding principle is "if it is important for monitoring system performance and you can measure it, you can easily integrate it into the PCP framework."
Similarly the Performance Co-Pilot tools for monitoring, visualizing, logging and reasoning about performance are all constructed from generic implementations that can be easily reconfigured or reused to customize the performance management tools and services to the local environment.
Complex systems are subject to continual reconfiguration of the network, hosts, software and services. Often these changes are asynchronous and remote. The distributed nature of PCP and the modular fashion in which the collection of performance metrics is managed allows PCP to readily adapt to changes in the deployed environment.
The PCP collection framework features a "plugin" architecture in which collection agents can be easily added to capture performance data from new sources, e.g. from an external device or a service utility or an end-user application. A library implements most of the default plugin functionality, with new agent development involving very little effort.
The performance data provider must be willing to externalize the information in some way, but PCP libraries and protocols place no practical limitations on how this should be done. For example, PCP collection agents have been constructed using all of the following:
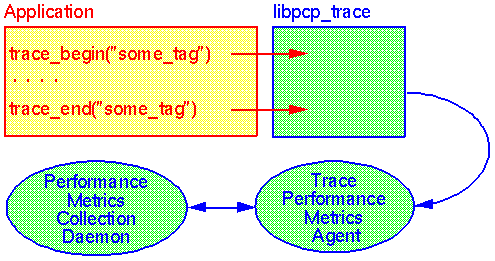
For applications where source code is available, another PCP library (libpcp_trace) supports a simple API for collecting measurements of application activity and aggregate elapsed time for arbitrary operations. The library automatically arranges for the collected data to be exported to the PCP framework using a purpose-built PCP collection agent (the trace agent).
Routines in libpcp_trace are callable from C, C++, Java or Fortran and provide the following services:
The architecture of an instrumented application and the associated PCP components is shown in Figure 5.
Additional capabilities of the library and the associated PCP collection agent provide:
As systems become more complex, the hard performance problems are less likely to be understood by using conventional tools and relying on intuition. Rather the hard problems will tend to be new, counter-intuitive and require the exploration of new relationships between performance metrics and the provision of new classes of performance metrics.
PCP addresses these challenges by providing a rich toolkit of building blocks which may be used to construct new tools and new perspectives on the performance data. For example the tools for automated reasoning, 2-D visualization, 3-D visualization and archive creation are all generic and capable of processing any performance data. These tools may be customized for specific problems or environments using simple configuration files with well documented formats.
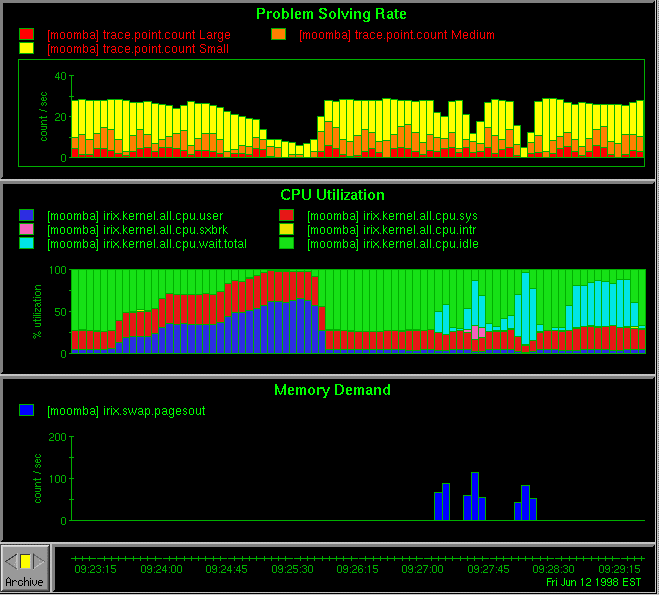
For example, the following stripchart configuration produces a display similar to that shown in Figure 6.
Chart Title "Problem Solving Rate" Style stacking
Plot Color #ff0000 Host * Metric trace.point.count Instance Large
Plot Color #ff8000 Host * Metric trace.point.count Instance Medium
Plot Color #ffff00 Host * Metric trace.point.count Instance Small
Chart Title "CPU Utilization" Style utilization
Plot Color #2d2de2 Host * Metric irix.kernel.all.cpu.user
Plot Color #e71717 Host * Metric irix.kernel.all.cpu.sys
Plot Color rgbi:0.9/0.1/0.5 Host * Metric irix.kernel.all.cpu.sxbrk
Plot Color rgbi:0.8/0.8/0.0 Host * Metric irix.kernel.all.cpu.intr
Plot Color rgbi:0.0/0.8/0.8 Host * Metric irix.kernel.all.cpu.wait.total
Plot Color #16e116 Host * Metric irix.kernel.all.cpu.idle
Chart Title "Memory Demand" Style bar
Plot Color #0000ff Host * Metric irix.swap.pagesout
The extensibility of the PCP collection framework encourages the provision of new performance metrics for those aspects of performance that are most useful in the local environment.
One of the areas in which this has proven particularly valuable is for measures of quality of service. If one is able to perform some small task that is indicative of a key aspect of system performance, then the elapsed time for the small task may be well correlated with total system performance as perceived by the end users. By executing this task periodically and exporting the measured performance we have a new and powerful performance metric.
This technique has been used to measure performance in the following areas:
The power of this type of measurement can be demonstrated by the following ways in which the information has been used:
The Message Passing Interface (MPI) is used to implement codes with coarse-grained parallelism, especially for engineering and scientific applications. The dynamic behavior of the parallel components of the computation is conceptually difficult to comprehend, particularly when the degree of parallelism becomes large.
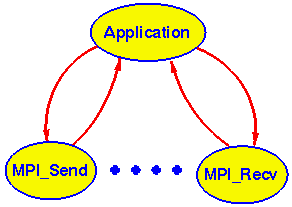
All communication and synchronization between the parallel components of an MPI job is via calls to routines in the MPI library to send messages, receive messages, rendezvous, etc.
If we consider the execution of each component to be modeled on a Finite State Automaton (FSA) as shown in Figure 7 then the behavior of the MPI job could be characterized by aggregating over all the components to establish the frequency of each state transition and the distribution of time spent in each state.
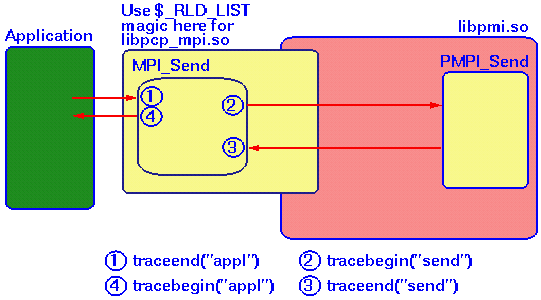
Silicon Graphics' MPI library (libmpi.so) is actually constructed "wrappers" for each routine to support debugging and calls from multiple programming languages. By using the capabilities of libpcp_trace and the IRIX dynamic loader rld, it has been possible to add instrumentation to an MPI job without recompilation or relinking as shown in Figure 8.
In this way the performance data from an MPI job was collected and exported into the PCP framework. This allowed the MPI performance to be visualized with standard PCP tools as shown in Figure 9. In this scene the MPI job has six parallel components and the height of the blocks in the foreground shows the recent distribution of times spent in selected MPI library routines. The cylinders are the rear of the scene show the instantaneous state for each of the parallel components using color modulation to match the blocks in the foreground, so at the moment one component is in send(), two are in recv() and three (the green cylinders) are executing application code, i.e. not in the MPI library.
Large systems provide challenging problems in the area of system-level performance monitoring and management. By combining a scalable infrastructure that can be customized to the needs of each site, the Performance Co-Pilot provides the required services and high bandwidth information filtering that is needed in this environment.
Performance Co-Pilot is a complex product that has been created by the efforts and vision of the Performance Tools Group members (past and present) and our vocal community of users who continue to challenge us to build better tools. To all of you, the author extends warmest thanks.
Ken McDonell is Engineering Manager of the Performance Tools Group of the Strategic Software Organization at Silicon Graphics Inc. A refugee academic, Ken has spent twenty-nine years exploring various aspects of computer systems performance, with a particular interest in operating systems, database management systems and pragmatic software engineering.
![]()