|
|

Link to slides used for this paper as presented at the conference. They are in Acrobat PDF format.
|
|
![]()
Michael Resch, Thomas Beisel, Holger Berger, Katrin Bidmon,

Allmandring 30
D-70550 Stuttgart
Germany
resch@hlrs.de
The first application we have run on the coupled T3E's is the flow simulation package URANUS. Problems and strategies with respect to metacomputing are discussed briefly for this code. Another application using this library isa Molecular Dynamics Code called P3T-DSMC. This program was developed for general particle tracking problems. We will present in this paper results for both applications.
A difficulty in simulating very large physical systems is, that even massively parallel processor systems (MPP) with a large number of nodes or parallel vector processors (PVP) may have not enough memory and/or not enough performance. There are many examples of these grand-challenge problems: CFD with chemical reactions or crash simulations of automobiles with persons inside. A possible way to overcome these limitations is to couple different computational resources. Although there are different definitions of metacomputing , this is how in the following we use this term.
In summer 1996 a G7 project motivated an attempt to couple Cray T3E's at Pittsburgh Supercomputing Center (PSC) and the University of Stuttgart (RUS) across the Atlantic Ocean to establish a virtual system with 1024 nodes and a theoretical peak performance of 675 GFlops. The PACX-MPI library [1] from RUS was used to allow an application to use standard MPI calls and work on this virtual machine. At Supercomputing'96 it was shown that the approach worked for a small demonstration experiment. During spring 1997 PACX-MPI was further developed and first application results could be presented at CUG '97 [6] .
At Supercomputing'97 the further progress was presented. A metacomputer consisting of the same machines like a year before and connected with a dedicated network connection with a bandwidth of two 2MBits/second enabled the demonstration of two real-life applications.
The first application is a flow solver developed at the University of Stuttgart [2] and adapted for parallel computation by RUS [5]. It was coupled to a visualization tool developed by RUS to allow collaborative working and visualization [3].
The second application was an object-oriented Direct Simulation Monte Carlo Code which was developed at the Institute for Computer Applications (ICA1) of University Stuttgart for general particle tracking problems. [4] .
Results with both applications point out, that a loosely coupled application like the latter one seems to be optimal for metacomputing. Nevertheless, it was shown, that even closely coupled applications, like a flow simulation, can be adapted for metacomputing, so that one can achieve satisfying results. [5]
To reach the metacomputing goals, a library called PACX (PArallel Computer eXtension) was developed at RUS as an extension of the message passing library MPI. The main goals of this library include
PACX-MPI redirects the MPI-calls to its own library. For applications written in C this is done by using a macro-directive, and for Fortran applications by using the profiling interface of MPI. Thus PACX-MPI is a kind of additional layer between the application and MPI.
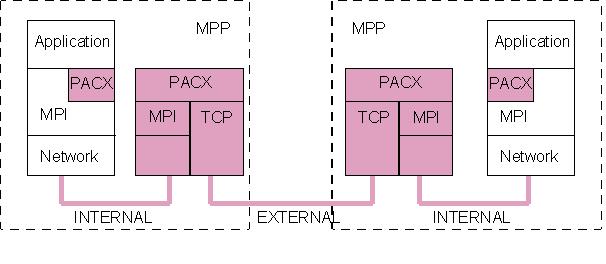
The PACX library determines whether there is a need for contacting the second MPP. If not, the library passes the MPI call to the local system unchanged, where it is handled internally. This guarantees usage of highly tuned vendor specific MPI implementations for internal communication. The overhead PACX imposes is very small on the CRAY T3E so that for calls on the local machine hardly any difference in performance can be seen.
To use PACX-MPI for an application, the user has to compile and link his application with the PACX-MPI library. No changes in code has to be done. The main difference for the user is the start-up of the application. First, he has to provide two additional nodes on each machine (like mentioned in the next section). An application which needs 1024 nodes an a T3E thus takes 2*514 if running on two separate T3Es.
Then he has to configure a hostfile, which has to be identical on each machine. The hostfile contains the name of the machines, the number of application nodes, the used protocol for the communication with this machine and optionally the startup command, if he wants to make use of the automatic startup-facility of the new version PACX-MPI 3.0. Such a hostfile may then look like this:
#machine number of nodes protocol start-up command
host1 100 tcp
host2 100 tcp (rsh host2 mpirun -np 102 ./exename)
host3 100 tcp (rsh host3 mpirun -np 102 ./exename)
host4 100 tcp (rsh host4 mpirun -np 102 ./exename)
For the communication between the two machines, each side has to provide two additional nodes, one for each communication direction. The responsibility of each communication node is to receive data from the compute partition of its machine or from the network respectively, to compress or uncompress the data, and then transfer data to the network or the local compute nodes. Data compression uses the library LIBLZO.
Communication via the network is done with TCP sockets. The concept of using two extra communication nodes (one for handling all outgoing communication and one for the incoming communication) has turned out to be a useful design, because it is easier to handle the complex communications needs of a real world application this way. Additionally it is getting more and more important to have only a limited number of ports for the external communication, because most of the real big machines nowadays are protected by some kind of firewalls. Therefore it makes sense to use only a small number of well known ports that can be easily monitored and controlled.
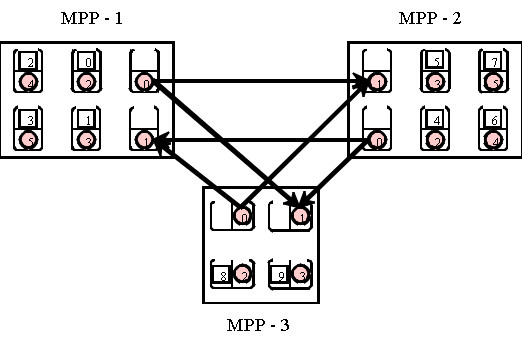
PACX provides an MPI_COMM_WORLD across all machines. The creation of such a communicator requires two different numberings for each node; a local and a global numbering. In the figure above the local numbers are written in the circles and the global numbers are written in the boxes. The two additional communication nodes are not considered in the global numbering and are therefore transparent for the application. To explain the function of the communication nodes, we describe the sequence of a point-to-point communication. In the example below the global node two sends a message to the global node seven.
In the previous PACX-MPI versions the receiver only checked, wether the sending node is on the same machine or not. For most situation this works well, but using more than two machines or different communicators this may lead to race conditions, where you need the possibility to buffer a message. For this, PACX-MPI 3.0 has a buffering system on the receiver node. The decision was to buffer messages without a matching receive on the application nodes rather than on a communication node, because this allows to distribute both memory requirements and working time.
The receiving node checks now first whether the expected message is an internal one. In case it is, it is received by directly using MPI. If it is an external message, the receiver node checks first whether the expected message is already in the buffer. If not, the message is received from the PACX-server.
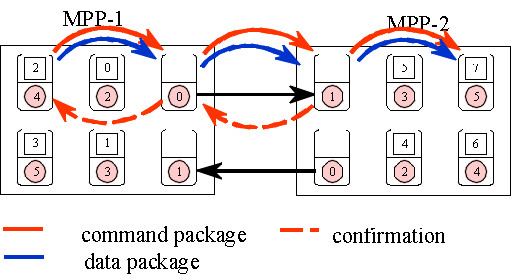
For global operations, the concept has changed from the older version PACX-MPI 2.0 to the newer one. In the old version, some parts of the global operations were executed by the communication nodes. This could lead under certain circumstances to a blocking of the application and therefore in the new Version PACX-MPI 3.0 the communication nodes are no longer involved directly into global operations.
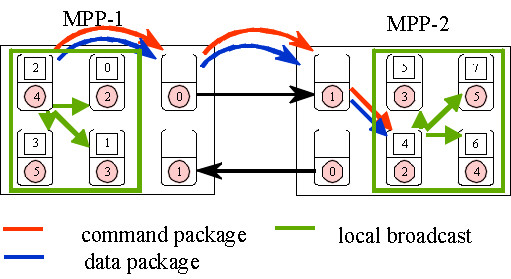
The sequence of a broadcast operation from global node 2 to MPI_COMM_WORLD is shown in the next figure. At first the root with the global number 2 sends a command-package and a data-package to the MPI-server. Then a local MPI_Bcast is executed. On the second machine the PACX-server transfers the command and the data-package to the node with the smallest number in this communicator on this machine. This node then does the local broadcast. This means that global communications are handled locally by nodes from the application part rather than by one of the servers.
So far PACX has been installed and tested on Cray T3E, Intel Paragon and Hitachi SR2201. Actually there is ongoing work to support heterogenous metacomputing, but nevertheless homogenous clustering will allways be faster and therefore PACX-MPI will enable the optimization of homogenous metacomputing.
To visualize metacomputing results tools for distributed visualization and control are needed in interactive metacomputing-scenarios. The HPC-center Stuttgart has a long tradition in distributed visualization and cooperative working. Within several EC-funded projects the distributed visualization system COVISE (COllaborative VIsualization and Simulation Environment) [3] has been developed. COVISE is a distributed multi process environment, that allows to integrate simulation with pre- and post processing steps across heterogeneous computing resources. A visual pro gramming paradigm allows to define the processing chain as depicted in the figure below. Typically the last processing step is a render module, which generates visual representations of a simulation content.
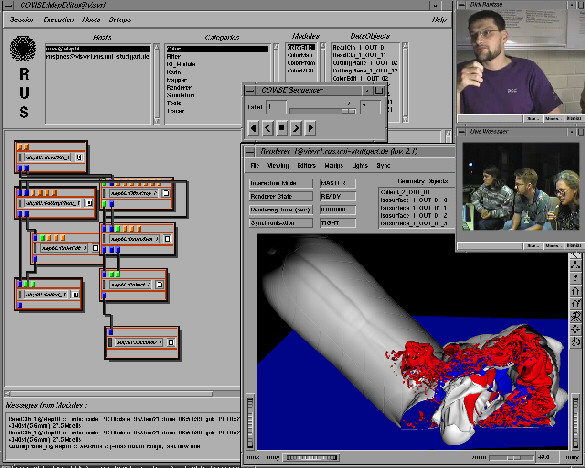
The Navier-Stokes solver URANUS (Upwind Relaxation Algorithm for Nonequilibrum flows of the Univeristy of Stuttgart) was developed at the Institute for Space Systems at the University of Stuttgart. It is used for the simulation of nonequilibrum flows around reentry vehicles in a wide altitude-velocity range. URANUS was chosen for our metacomputing experiments because the simulation of reentry vehicles requires an amount of memory that can not be provided by a single machine.
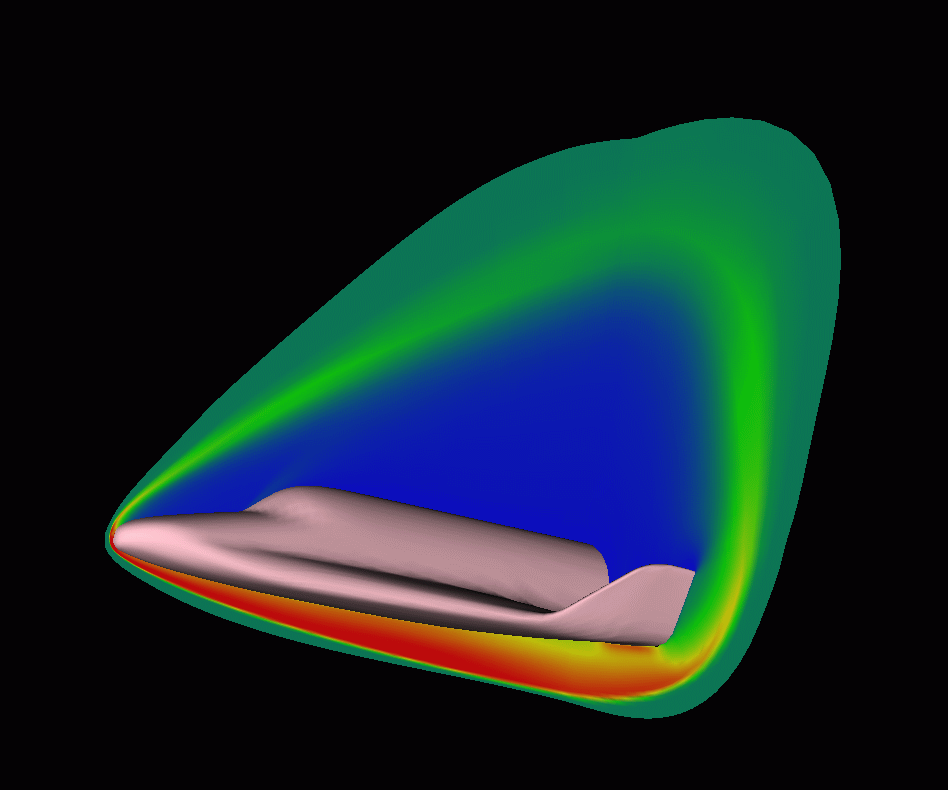
To compute large 3-D problems, the URANUS code was parallelized at RUS. Since the code is based on a regular grid a domain decomposition was chosen. This results in a perfect load balancing and an easy handling of communication topology. An overlap of two cells guarantees numerical stability of the algorithm.
Initially the code was split into three phases (preprocessing, processing and postprocessing). Preprocessing was done sequentially. One node read in all data, did some preprocessing work, and distributed data to the other nodes. For the tests the Cray T3E of the Pittsburgh Supercomputing Center and the Cray T3E of the Stuttgart University were coupled using a dedicated network connection with a bandwidth of 2 Mbits/second and a physical latency of about 70 ms.
In the following we give the overall time it takes to simulate a medium size problem with 880.000 grid cells. For the tests we simulated 10 Iterations. We compared a single machine with 128 nodes and two machines with 2 times 64 nodes.
|
Method |
128 Nodes using MPI |
2*64 Nodes using PACX-MPI |
| URANUS unchanged |
102.4 |
156.7 |
| URANUS modified |
91.2 |
150.5 |
| URANUS pipelined |
- |
116.7 |
Obviously the unchanged code is much slower on two machines compared with the execution time on a single machine. However, the overhead of 50% is relatively small with respect to the slow network. The modifed URANUS version, which uses fully asynchronous message passing improves the execution time for both cases. Using the so called "Message pipelinig" [5] messages are only received if available. The receiving node may continue the iteration process without having the most recent data. This helped to reduce the computing time significantly but for convergence the number of iterations had to be increased by about 10%. Using this final version, a full space vehicle configuration using more than 1 million grid cells was run on 760 nodes during Supercomputing '97.
The second application is P3T-DSMC. This is an object-oriented Direct Simulation Monte Carlo Code which was developed at the Institute for Computer Applications (ICA1) of the Stuttgart University for general partickle tracking problems. Since Monte Carlo Methods are well suited for metacomputing, this application gives a very good performance on the transatlantic connection.
|
Particles/CPU |
60 Nodes using MPI |
2*30 Nodes using PACX-MPI |
| 1935 |
0.05 |
0.28 |
| 3906 |
0.1 |
0.31 |
| 7812 |
0.2 |
0.31 |
| 15625 |
0.4 |
0.4 |
| 31250 |
0.81 |
0.81 |
| 125000 |
3.27 |
3.3 |
| 500000 |
13.04 |
13.4 |
For small numbers of particles the metacomputing shows some overhead. But up to 125.000 particles timings for one time step are identical. During SC'97 this application was able to set a new world record for molecular dynamics simulating a crystal with 1.4 billion particles on two T3E using 1024 processors. This proved that metacomputing can be a tool to further push the frontiers of scientific research.
At the end of April 1998 another test was done with this application coupling a Cray T3E/600 with 512 nodes of the High Performance Computing Center in Juelich, a Cray T3E/900 with 256 nodes of the same institution and the Cray T3E/900 with 512 nodes of the High Performance Computing Center in Stuttgart. P3T-DMSC ran successfully on this cluster. This test pointed out, that the new PACX-MPI version is able to couple more than two MPPs.
We have shown that two T3E's can be successfully coupled even across the Atlantic Ocean and more than two MPPs are able to work on the same problem using the PACX-MPI library. We have shown that PACX-MPI works correctly, and the concept can be extended for heterogenous metacomputing.
URANUS has been shown to scale well on large numbers of nodes. Contemporaneously we've shown, that although one can use your code unchanged to do metacomputing, one can achieve a much better performance if you use asynchronous message passing or do some latency hiding. Especially for such a closely coupled application it makes sense to adapt the code for metacomputing.
P3T-DSMC is a loosley coupled application and therefore optimal for metacomputing. Applications like this, based on Monte Carlo Methods, show a very good performance even for long distance connections.
The ongoing work with PACX-MPI intends to support heterogenous metacomputing, too. The data-conversion routines are implemented and are now in the testing phase. Another main research field tries to improve the external network performamce, and therefore in the near future PACX-MPI will support other network protocols in addition to TCP/IP. An other possible direction of PACX-MPI may also be to support a part of the functionality of MPI-2, expecially the dynamic process start would be of very big interest for metacomputing.
michael m. resch received his diploma degree in technical mathematics from the technical university of graz/tria in 1990. from 1990 to 1993 he was with joanneum research - a leading austrian research company. since 1993 he is with the high performance computing center stuttgart. where he was and is involved in the european projects caesar and hps-ice. furthermore he is responsible for the development of message-passing software and numerical simulations in international and national metacomputing projects. since 1998 he is head of the parallel computing group of the high performance computing center stuttgart. his current research interests include parallel programming models, metacomputing and numerical simulation of viscoelastic fluids.<>
thomas beisel is a member of the system administration group of the high performance computing center at stuttgart (hlrs)<>. He received the diploma degree in Mechanical Engineering from the University of Stuttgart in 1996. His diploma thesis was the initial version of the PACX-MPI library.
holger berger was a mathematical technical assistent at the university of stuttgart. since 1998 he is with nec focusing on programming models.<>
katrin bidmon is currently studying mathematics at the university of stuttgart and is working now for nearly one year in the software development group of the pacx-mpi project, where she is responsible for data-conversion problems and heterogenous metacomputing.<>
edgar gabriel is working since 01.06.98 with the parallel computing group of the high performance computing center in stuttgart. there he is responsible for the parallel program development in the sfb 259 (uranus) and part of the software development group of the pacx-mpi project. he got his dipl.-ing. for mechanical engineering of the university of stuttgart in 1998.<>
rainer keller is actually studying computer science at the university of stuttgart. he is working since more than one year with the software development group of the pacx-mpi project and is the main programmer of the latest pacx-mpi version.<>
dirk rantzau received the diploma degree in mechanical engineering from the university of stuttgart in 1993. from 1993 to 1994 he was involved in the race project pagein where he worked in the field of interactive steering of supercomputer simulations and collaborative working at the high performance computing center of the university of stuttgart. since 1995 he is working in the collaborative research center rapid prototyping established at the university of stuttgart in the field of vr based virtual prototyping. his current research interests include collaborative virtual environments for scientific visualization, 3d user interfaces and interaction techniques for computational steering.<>
The authors gratefully acknowledge support from their home organizations HLRS and from PSC, as well as supercomputing time provided by Forschungszentrum J¸lich GmbH.
![]()