bettge@ucar.edu
www.cgd.ucar.edu/pcm/
Over the past two decades the U.S. Department of Energy (DOE) has sponsored climate modeling research activities aimed at addressing the potential impact of man-induced climate changes and developing energy use strategies. The goal of the DOE activity in the past three years at the National Center for Atmospheric Research (NCAR) was to construct a climate system model, targeting MPP (massively parallel processor) and DSM (distributed shared memory) machines, by exploiting previous DOE-supported parallel modeling efforts developed under the program on Computer Hardware, Advanced Mathematics, and Model Physics (CHAMMP). In late 1997 this effort culminated with the emergence of the Parallel Climate Model (PCM).
The PCM is a fully coupled climate system model and includes numerical models of the atmosphere, land, ocean, and sea ice. The early target architecture of the PCM was the Cray T3E900 at the National Energy Research Supercomputing Center (NERSC). After initial tests on the T3E, it became apparent that SGI Origin 2000/128 (O2K) systems would be available at NCAR and the Los Alamos National Laboratory (LANL). Thus, while the PCM was initially a distributed memory code using the SHMEM on the T3E, it was quickly and easily ported to the O2K by installing and implementing the industry standard Message Passing Interface (MPI).
The primary purpose of this paper is to describe performance of the PCM on the T3E and O2K.
The long production integrations of the PCM are performed on the O2K machines at NCAR (250MHz, 128pes, 16GB memory) and at LANL (250MHz, 128pes, 32GB memory), and on the T3E900 (792pes, 256 MB memory per pe) at NERSC.
The PCM consists of four basic climate component models - atmosphere, land, ocean, and sea ice - which are coupled via a facility known as the flux coupler.
The atmospheric model is the NCAR Community Climate Model, Version 3.2, which is used with a horizontal resolution of T42 (equivalent to a grid spacing of about 3 degrees) and 18 vertical levels. The model was originally built for Parallel Vector Processor (PVP) architectures, but was modified for MPP use (Cray T3D/T3E) employing a one-dimensional data distribution decomposition in physical space according to latitude line. The T42 resolution contains 64 Gaussian latitude lines, limiting the multiple processor use to 64 processors. The basic design and a summary of the performance of this model is given by Hack[1]. The land model is currently embedded in CCM3.
The ocean model is the LANL Parallel Ocean Program (POP)with a horizontal grid resolution of approximately 2/3 degree and 32 levels in the vertical. The projection of the horizontal grid over the globe is accomplished by displacing the numerical pole away from the North Pole to eliminate the polar discontinuity caused by the convergence of meridians, thus allowing a longer temporal step in time.
DOE collaborators at the Naval Postgraduate School (NPS) developed the model of sea ice. The model consists of both ice thermodynamics and full dynamics. Physically, the model is two-dimensional with a stereographic grid over each pole at a horizontal resolution of 27km.
The flux coupler is the connecting mechanism between the component models which facilitates the exchange of information (i.e., state variables as well as heat, water and momentum fluxes). The process involves the conservative mapping of data from one grid to another, averaging in space and time as needed, and scaling the fluxes such that total energy is conserved. Special computational issues with the coupler are driven by the physics of the problem. That is, interaction between components is restricted to the time and space scales which must be resolved. Computationally, the flux coupler is latency bound due to the need for global reductions and post-mapping barriers.
Because the primary goal of the PCM project is to produce useful simulations of the earth's climate, and not necessarily to reinvent or rewrite complicated component codes, the construction of the PCM is limited to existing models. While the models do have a high level of sophistication aimed at the target machines, they were developed by different groups with somewhat different goals. The final construction and deployment of the PCM was constrained by these limitations.
Early in the design phase of the PCM, a decision concerning the level of model parallelism was necessary. Due to the difficulty in communicating between partitions on the T3D/T3E (somewhat constrained by the operating system), it was decided to execute the models sequentially in a single executable. While this solution is the less interesting computational science problem, it avoids the issue of load imbalance at a high level between model components. In addition, sequential execution has the advantage of maximizing processor use, and porting the code to different machines (with different operating systems and/or batch system priority schemes) is made easier.
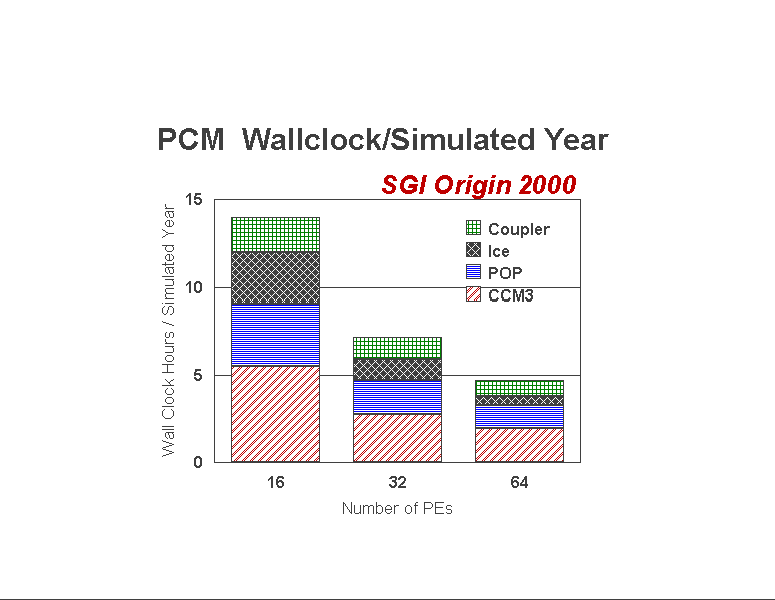
Figure 1 shows the amount of wallclock time required by the PCM and its components to complete a one-year simulation on 16, 32, and 64 processors of a dedicated O2K. Note that the CCM3 requires most of the time, followed in order by POP, the coupler, and finally the sea ice. As with any problem the size and scope of the PCM, the priorities of computational design and improvement are driven in part by the relative importance of the problem. For example, computational issues with the ice model have been less important and given less attention than issues with other components.
The performance of the PCM on the SGI and the T3E, when compared and contrasted, reveal differences which are significant, yet not unexpected. The dedicated performance of the PCM is summarized first, followed by a short analysis of the PCM performance in batch production on the O2K. It should be noted that the inherent partitioning architecture of the T3E allows that dedicated performance and batch performance are virtually identical with few exceptions, such as a system checkpoint/restart procedure during an extended integration.
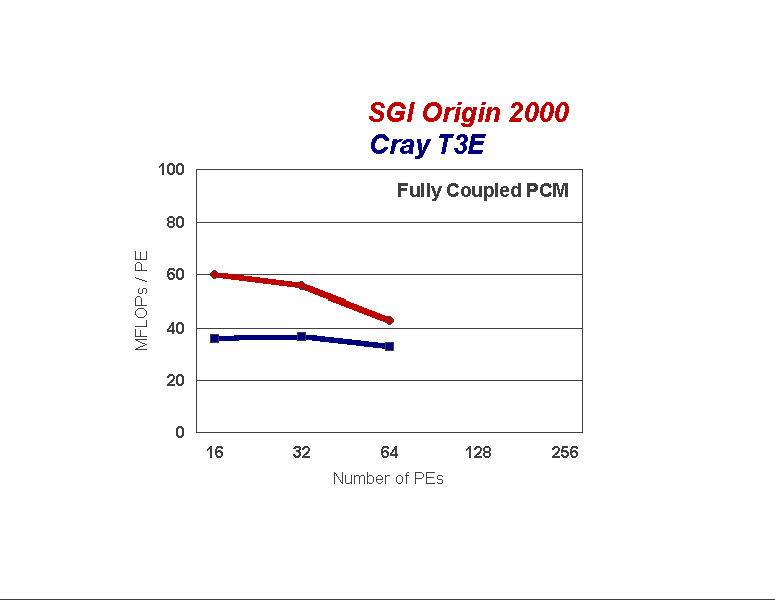
The dedicated performance of the fully coupled PCM is shown in Figure 2. For 16, 32 and 64 processor tests, the model achieves higher performance rate on the O2K, which presumably is the result of more efficient use of processor cache, memory bandwidth, and processor utilization on the O2K. Note that the PCM does not scale completely from 32 to 64 processors on either machine, and does not scale as well on the O2K as on the T3E. The reasons for the lack of scalability is discovered by looking at the individual components.
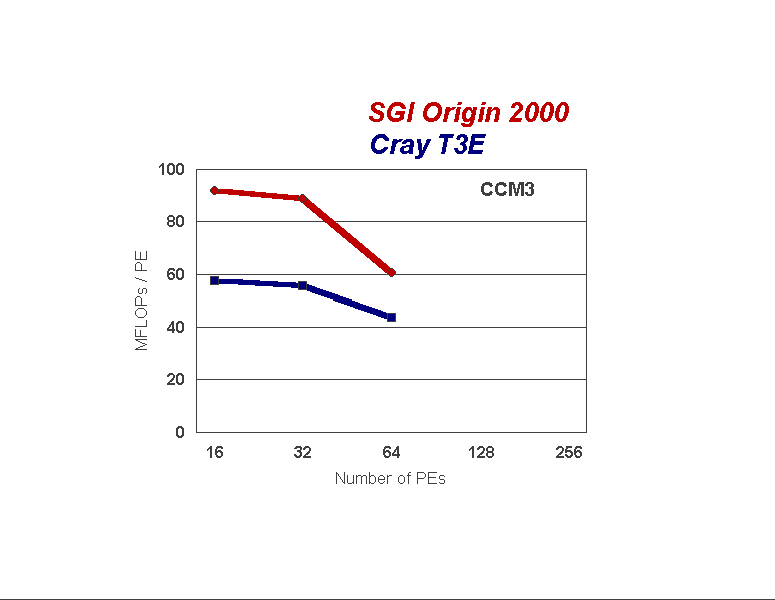
Figure 3 shows the performance of CCM3. As discussed earlier, the data decomposition of CCM3 as well as the workload imbalance created at T42 spectral truncation, causes the relative decrease in scalability to 64 processors. We attribute the relatively lower scalability on the O2K to the less efficient communication performance on the O2K (noted by others, see [2]). The CCM3 carries the largest workload of the four components (Figure 1), and achieves the highest rate of performance, which is not an undesirable feature of the PCM!
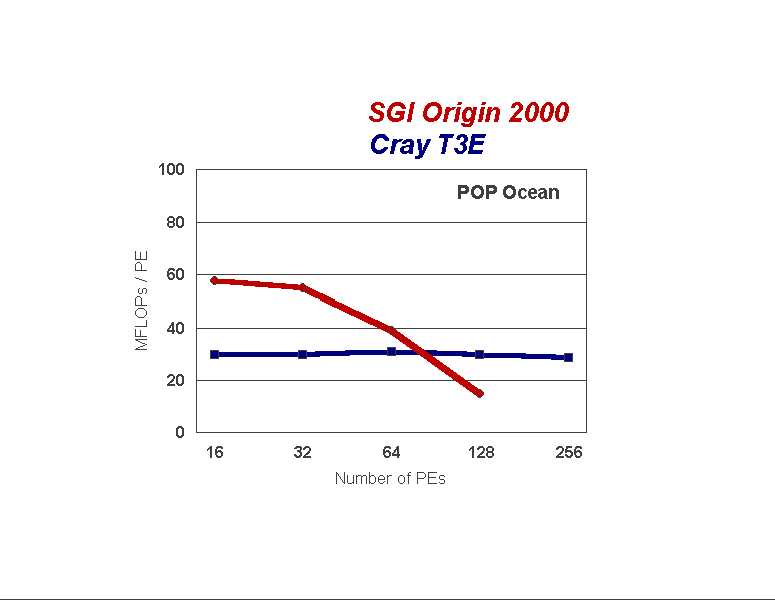
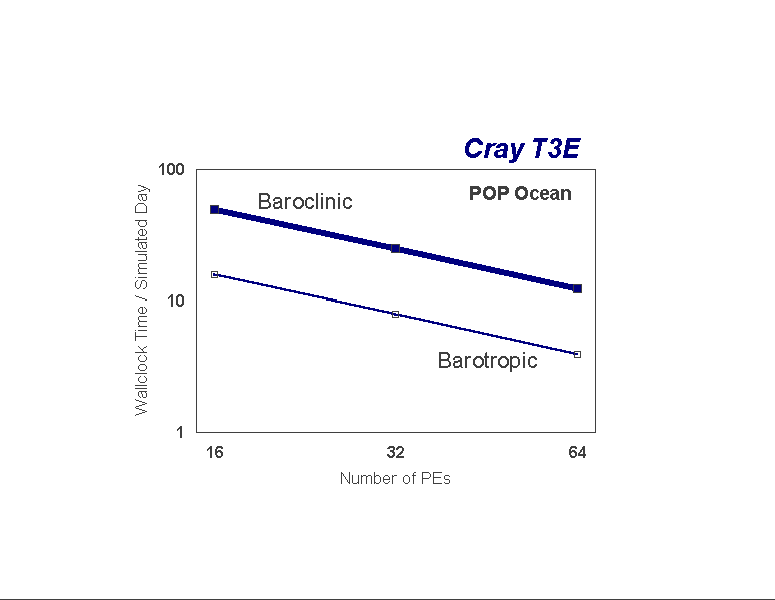
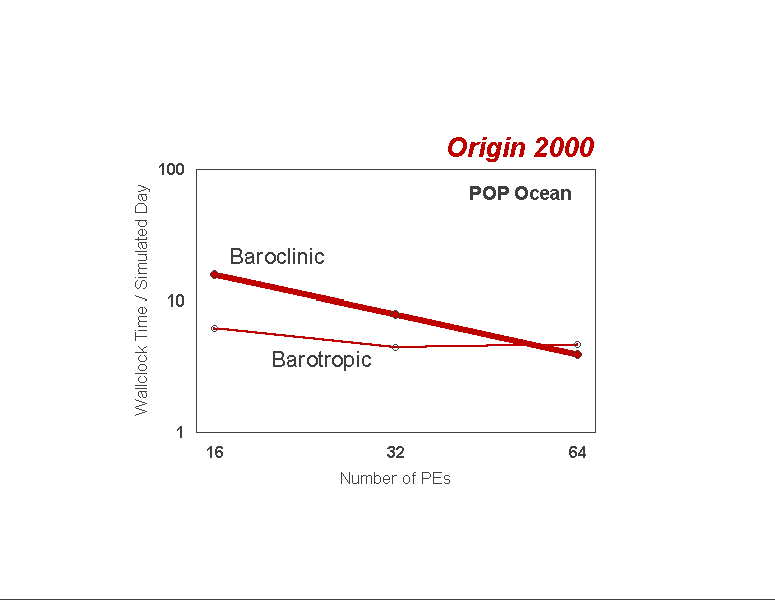
The POP ocean model performance is illustrated in Figure 4. A standalone version of POP was used to extend the performance tests beyond 64 processors, the results of which have been added to this diagram. POP scales extremely well on the T3E, but poorly on the O2K. During each timestep of the POP integration, the majority of the computational time is taken to solve for the baroclinic and barotropic motions in the ocean. The baroclinic mode is solved explicitly at every grid point and is computationally intensive, but the barotropic mode involves the solution of an elliptic equation involving hundreds of convergence iterations each day, each requiring two global reductions. Thus, the barotropic solver involves a relatively large amount of communication. On the T3E, as shown in Figure 5, both the baroclinic and barotropic solutions scale linearly. However, as conveyed in Figure 6, on the O2K the baroclinic solution scales linearly while the barotropic solver scales poorly, resulting in the apparent lack of scalability on the O2K. The problem is is related to either communication latency, or a load imbalance, involving the MPI_allreduce. Others have reported the relative drop in MPI performance on the O2K compared to the T3E as the number of processors has increased. [2]
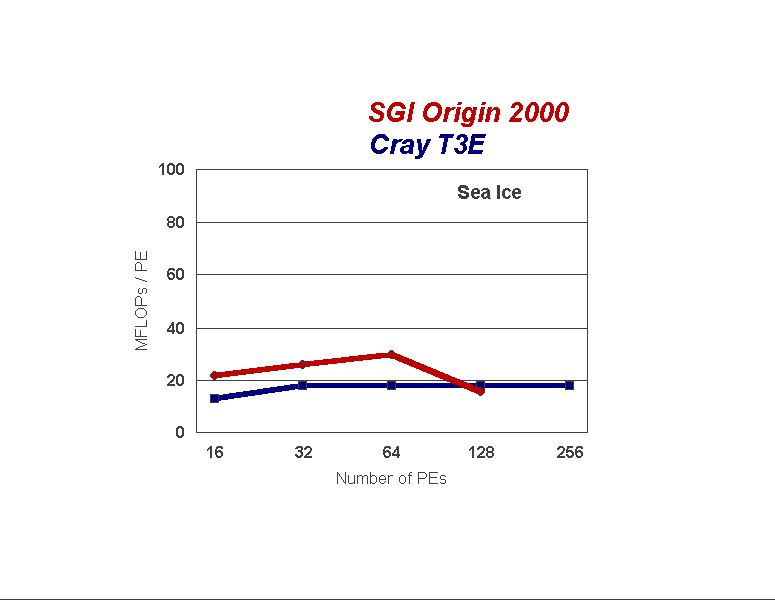
The sea ice model performance, shown in Figure 7, shows an apparent super-scaling from fewer to more processors. The problem is straightforward. The dense data decomposition size is too large to fit in cache on lower numbers of processors, resulting in cache misses. Once the data decomposition partition reaches a size compatible with cache, the ice model scales linearly. Again, a standalone version of the ice model was used to generate performance numbers above 64 processors. On the O2K, the ice model suffers similar communication problems described in the ocean model.
During batch production integrations of the PCM on the O2K, at both NCAR and LANL, we quickly realized that the performance observed during dedicated testing was difficult to match. Typically, unless the machine falls idle aside from the PCM job itself, a performance degradation of 10-100% is observed, and depends upon factors such as the number of jobs, the types of jobs, and the subscription of memory and processors. The PCM also experiences nearly 100% degradation after a system checkpoint/restart under IRIX 6.5.3 (and earlier versions of IRIX).
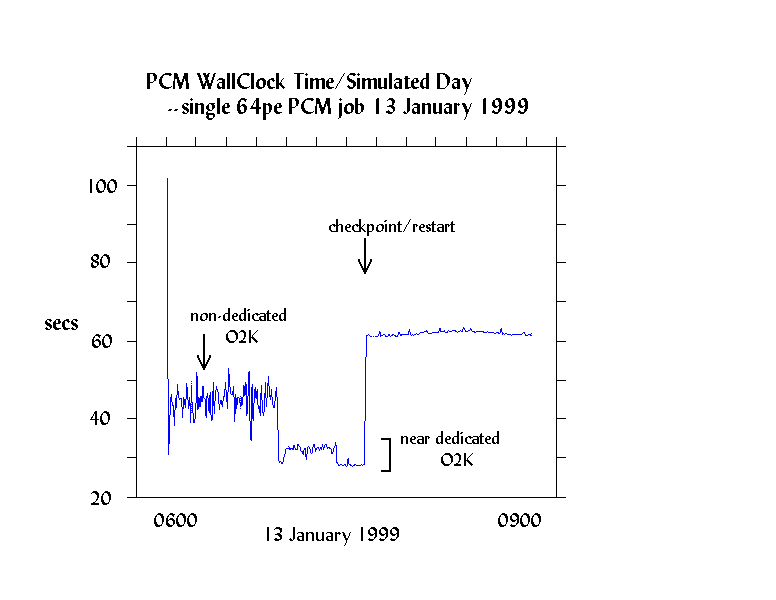
The affect of many of the external influences upon the PCM on the O2K was captured during a single PCM job during a three-hour period in January 1999 at NCAR, and is shown in Figure 8.
Note the three distinct performance levels experienced by the single job. First, the PCM was competing for resources with another 64 processor application early during the period, and suffered a 35-40% degradation due to competition for resources. Next, when the first competing job exited, another job entered but did not compete nearly as intensely for resources. The second job then exited, leaving the PCM to run on a near-dedicated machine for several minutes. Finally, the PCM was checkpointed and restarted by the system, after which the performance was only half of it's pre-checkpoint value.
It should be noted that the PCM batch job shown in Figure 8 was running in the batch queue without the use of special system tools or environment variables designed to avoid inefficient performance. We have subsequently found that the implementation of the dplace, a NUMA memory management tool, can be used to eliminate contention for O2K memory and processor resources. However, dplace can be used effectively only when the control of the machine environment is restricted (for example, when a single user controls the entire machine).
Finally, recent testing has shown that the checkpoint/restart issue has been eliminated with the release of IRIX 6.5.4.
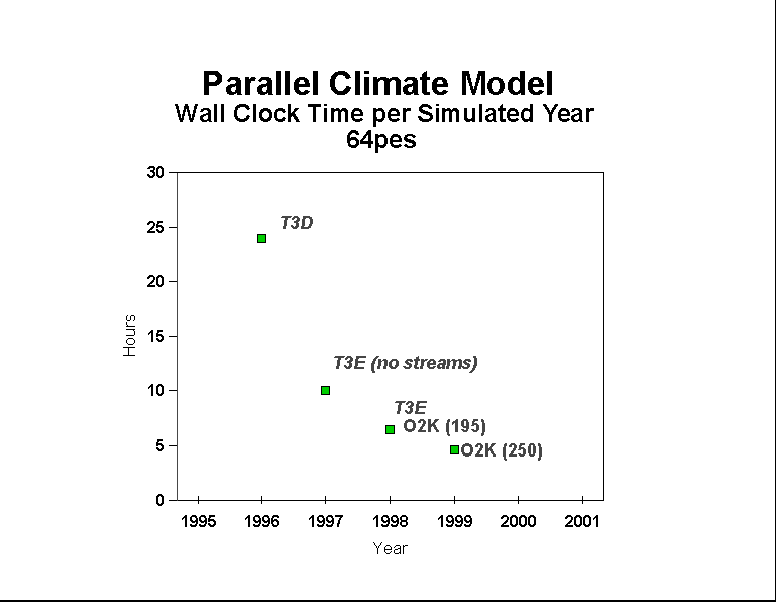
Performance of the PCM as measured in wallclock hours per simulated year on 64 processors is shown in Figure 9 for the series of Cray and SGI machines available to the project since it's inception in 1996. Over three years, the wallclock time to complete a simulated year with the PCM has dropped from one day (T3D) to under 5 wallclock hours (O2K), a significant and noteworthy improvement considering that multi-century simulations are needed for contemporary climate investigations. Through hardware, software, and algorithm improvements, there is no reason to expect this trend will not continue.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}