Manager, Software Engineering, SGI
NERSC Systems Group
There have been many changes in application scheduling support on the Cray T3E since UNICOS/mk 2.0.3. A majority of the effort has been in the areas of stabilization and performance of the scheduling components, but there have also been a few general improvements that will allow sites to simplify their local efforts to improve the overall utilization of their Cray T3E application PEs (Processing Elements). These improvements are the primary focus of this paper, though some change has occurred since the submission of the abstract.
Just prior to the 1999 CUG Conference in Minneapolis, a collaborative effort between NERSC (National Energy Research Scientific Computing Center) and SGI achieved significant success in maintaining relatively high MPP system utilization. The scope of this paper and the talk have been altered to allow the presentation of NERSC's perspective. We would like to offer a special thanks to Mike Welcome from NERSC and Steve Luzmoor (SGI) for their significant contributions in documenting this effort.
The first portions of this paper briefly discuss, at a very high level, the basics of application scheduling on the Cray T3E. Following that, the notable UNICOS/mk 2.0.4 and 2.0.5 scheduling features1are defined. The remaining sections discuss in detail the experiences at NERSC.
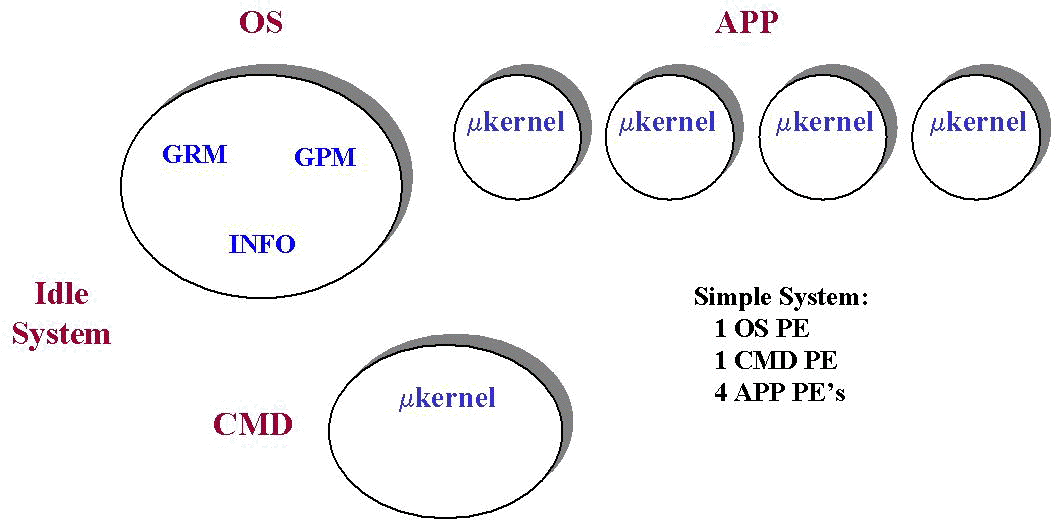
To provide a framework for understanding, the following simple Cray T3E configuration will be utilized throughout the following sections. Experienced users and administrators may want to skip to the first section discussing the UNICOS/mk 2.0.4 Scheduling Enhancements.
Figure 1, shows a simple Cray T3E containing one OS PE, one CMD PE, and 4 APP (application) PEs. Each PE contains a microkernel and a subset of operating system (OS) servers to manage local OS functions. While each processor functions independently (providing the framework for the scalability of the T3E), certain functions require global data and synchronization to maintain a single-system image (SSI). These latter functions are provided by servers running on the OS PEs. The single OS PE in this configuration contains, among other essential servers, the Global Resource Manager (GRM), the Global Process Manager (GPM), and the Information (INFO) server.
Figure 1:Simple Cray T3E
With the initial release of UNICOS/mk, all necessary functions for running commands and applications were provided. When a user logged into the system, their shell was exec'd to a CMD PE as were all single-PE programs. To launch a multi-PE application, the users either built their application to execute on a specific number of application PEs and exec'd it, or they linked a malleable binary which could later be run on a requested numbers of PEs via the mpprun(1) command.
Figure 2 shows the high-level flow of requests necessary to launch and run a multi-PE application. The user executes the mpprun(1) command in their shell requesting that the a.out binary be allocated 4 APP PEs. The local microkernel communicates with the GRM and GPM to obtain global process ID and APP PE resources (step 1). Once the resources are assigned, a.out is sent, using a remote exec call, to the base PE of the allocated region (step 2). After being constructed on the base PE, the process image is cloned to the remaining PEs and the application reaches an initial synchronization point (step 3). Since only one process is allowed to exist on each APP PE, the corresponding microkernels choose to run the only available process and the application begins its implicit synchronized execution.
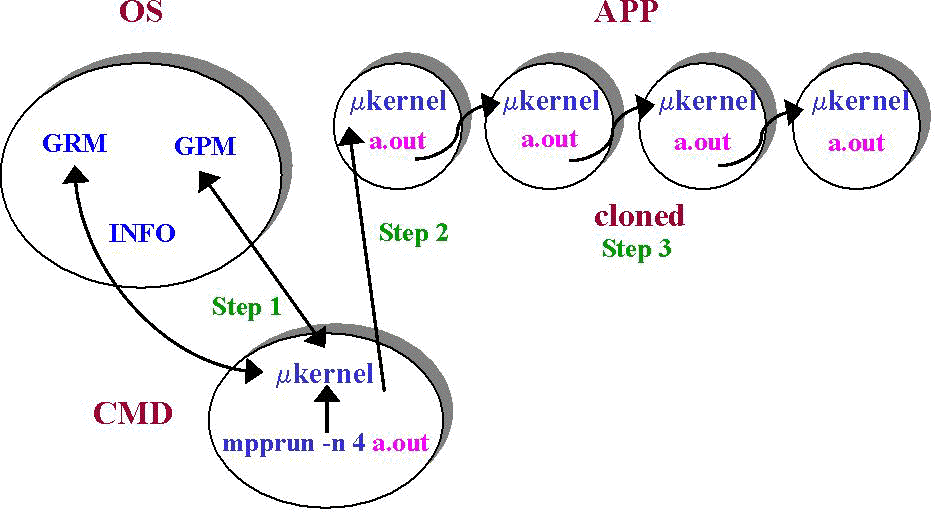
Figure 2: One Application
The Political Scheduling Daemon (PScheD) was first released with UNICOS/mk 2.0. PScheD has four major functions:
These functions can be separately configured. For example, it is quite common for a small Cray T3E with minimal swap space to run only the Load Balancer to reduce fragmentation in the APP PE region. If the site wishes to run more than one application on a PE and/or allow for the preemption of applications in favor of very high priority work, they must configure the Gang Scheduler. In the preemption case, they must also configure the Resource Manager.
When the Gang Scheduler is configured, the GRM (Global Resource Manager) configuration can be altered to allow more than one application to be allocated to each APP PE. When the Gang Scheduler starts, it communicates with the APP PE microkernels and informs them that user process scheduling decisions will be made by the daemon. Then, at configurable time intervals, the Gang Scheduler communicates with the INFO server to gather global process and application information (step 1 in Figure 3). Given this data, it determines which application should be allowed to run for the next time slice. It then communicates with the appropriate microkernels to insure that the selected applications are loaded and made simultaneously runnable (step 2). It should be noted that without this rather heavy-handed approach by PScheD, applications would not likely make consistent forward progress as one microkernel may choose to run a.out while another selects b.out. Much more serious consequences can befall the applications when swapping is involved and concurrent execution is not guaranteed.
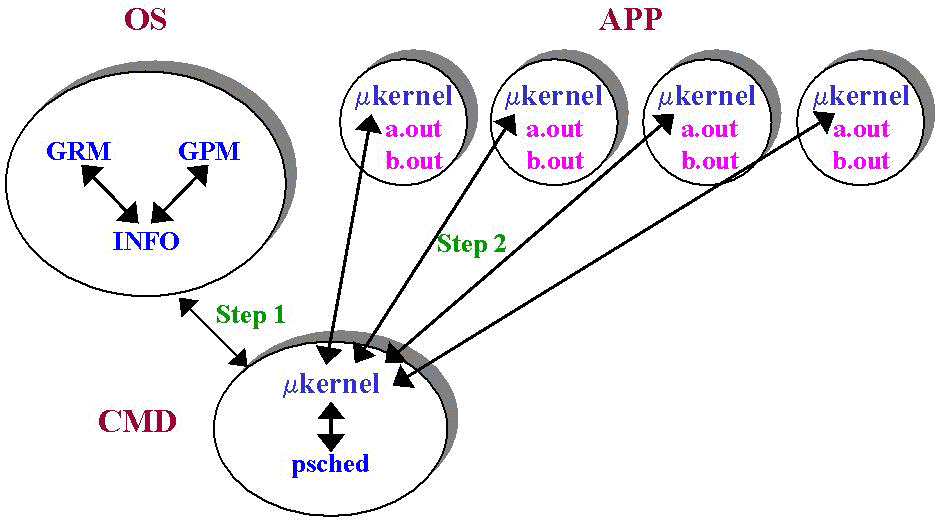
Figure 3: Two Applications with Gang Scheduling
With GRM configured to run multiple applications, the Load Balancer must also be concerned with reducing the numbers of parties (collections or levels of multi-PE applications) as well as reducing fragmentation. Figure 4 shows an initial state with two, 2-PE applications a.out and b.out residing on the first two PEs in the APP region. Without the Load Balancer's intervention, the Gang Scheduler would continue to time slice the applications even though idle PEs were available. Again, at configured intervals, the Load Balancer gathers global information about processes and applications from the INFO server (step 1). It then determines migration scenarios which improve the state of the APP region. Once a move is determined, the Load Balancer, via the migrate(2) system call, requests that the appropriate microkernels perform the desired migrations (steps 2 and 3) of processes in the application. After the migration of b.out,both applications are scheduled by the Gang Scheduler to run without competition.
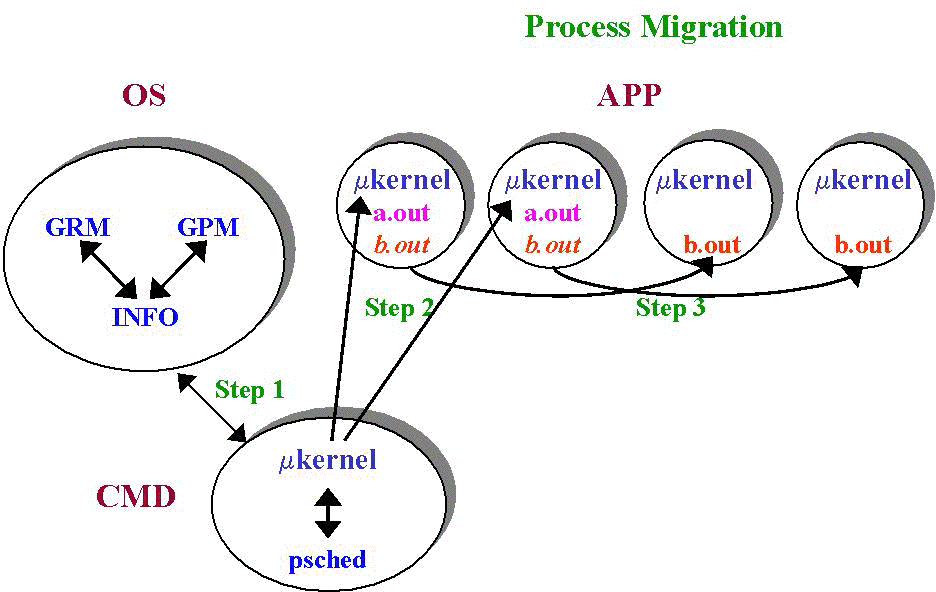
Figure 4: Two Applications with Load Balancing
As noted earlier, the primary function of the PScheD Resource Manager is to maintain information on prime jobs and insure (with help from the Gang Scheduler) that applications which are part of prime jobs are scheduled as quickly as possible and without competition from normal work. Prior to this release, the prime status was known only to PScheD. With 2.0.4, the prime status of a job is propagated to the kernel-level structures which allows preserving the status across checkpoint/restart operations. The status also became visible via the jstat(1) -s command and is shown by the ps(1) SPRIME flag.
The following PScheD Gang Scheduler features were incorporated into UNICOS/mk 2.0.4:
DDDD
AAAAAAAAAAABBBBCCCCCCCCCC
to:
DDDD
AAAAAAAAAAABBBBCCCCCCCCCC
This allows application A to run during every gang scheduling slice as opposed to idling 7 PEs while application D is chosen to run.
We felt that single-PE applications would also be useful at sites that had large memory commands which ran as part of a user's job. These large commands often make load balancing on the CMD PEs difficult.
At UNICOS/mk 2.0.4, APP PEs can be configured by GRM to allow single PE applications. They are scheduled and accounted for as applications - accumulating MPP connect time.3 The Load Balancer also recognizes and appropriately deals with them as part of the multi-PE load balancer function. The user may launch a single-PE application with
the following command:
The single-PE application attribute is also inherited, meaning that if another binary is forked or exec'd from a.out, it too will be launched as a single-PE application without special requirement of the user.
A snapshot option (-s) was added to the grmview(1) command to capture the current GRM configuration. The output can be edited and executed to affect a configuration change.
The GRM scheduler can be configured with 2.0.4 to run in variations of FIFO and eager scheduling modes. A complete description of these modes is beyond the scope of this paper. 4
The UNICOS/mk 2.0.5 release, scheduled for 3Q1999, continues efforts to allow better utilization and improved response time for applications running on the Cray T3E.
GRM Scheduling Enhancements (2.0.5)
Three GRM enhancements are included with UNICOS/mk 2.0.5:
- Application Mini-Launch - Previously, when a large application launched, an in-progress Gang Scheduler request was suspended until the launch could be completed. If swapping was necessary, this could take a considerable amount of time. Worse yet, if the Gang Scheduler chose not to run the newly launched application, it might be swapped out causing another delay. Mini-launch allows an application to be placed on the base PE of its allocation with minimal memory requirements. It will remain in this state until the Gang Scheduler chooses to run it, at which time the launch will progress during the user's scheduled time slice.
- GRM Load-n-Go with psched - While the Gang Scheduler was in the process of effecting a scheduling change, no activity (application launch) was allowed anywhere in the APP PE domain. This change allows an application to be launched and immediately begin execution on idle PEs while a gang scheduling change is in progress. This can be particularly useful for short debug applications. Prior to this feature, the Gang Scheduler had to explicitly schedule the application before it would begin execution.
- Global Service Provider Limits - Many sites have attempted to separate the APP PEs for batch and interactive work. This was done in an attempt to reserve and/or guarantee resources to certain groups of users. This kind of configuration often prevented the Load Balancer from accomplishing its intended task and resulted in idle PEs when not all groups of users were active. The Global Service Provider Limits feature allows sites to configure a global limit by service type for the APP PE region. Its definition and use are best described by the experience at NERSC. See NERSC T3E Scheduling Configuration after the UNICOS/mk 2.0.4 Upgrade below.
Application Load Balancer (LB) Enhancements (2.0.5)
Under certain scenarios, the Load Balancer might attempt to migrate the same application repeatedly, even when the application could not be migrated for some reason. This release provides a configurable error delay timer for migrations that cannot be successfully completed. The Load Balancer status display has been enhanced to show the current error and the amount of time remaining until the next migration attempt will be allowed for that application.
Administrators have also been often frustrated when they discover a scenario that should be corrected by a multi-step migration -- move A, then B, then C. (Reasons for why the Load Balancer was not designed for this are beyond the scope of this paper.) If a short Load Balancer time slice was configured, the adminstrator could find that the migration they effected with the migrate(8) command was promptly undone by the Load Balancer. Changes were made to allow the Load Balancer to recognize that an application was moved (by someone or something other than itself) and to apply the configurable migration delay so that it would not choose the same application for remigration.
Gang Scheduler Enhancements (2.0.5)
The Gang Scheduler was enhanced to allow sites to configure the amount of system overhead they will allow when swapping is necessary for gang scheduling context switches. Consider the following equation:
slice_time = config_slice_time +
(switch_time * variation)Sites may configure the gang scheduling time slice (config_slice_time) and the variation. The switch_time is the amount of time necessary to affect the context switch. If swapping is involved, switch_time can be quite large. If no swapping is necessary switch_time is less than a second (even on large Cray T3Es) or effectively zero (0) in this calculation. So, for example, if config_slice_time was 60 seconds, the variation was set to 20 and no swapping was necessary, the next scheduled context switch would occur in 60 seconds:
60 seconds = 60 seconds + (0 * 20)
But, if the context switch took 60 seconds, the next context switch would not be scheduled for over 20 minutes:
1260 seconds = 60 seconds + (60 seconds * 20)
When the conditions causing the swapping are relieved through migration or application exit, the context switch time will return, in this example, to 60 seconds without administrator intervention.
One of the major benefits of this feature is that when swapping is not necessary for context switches, fairly small time slices can be achieved to facilitate application debugging.
Two features which had been planned for the initial release of UNICOS/mk 2.0.5 may not be made available until 1Q200.
Ability to affect applications in GRM queue with mpprun(1) options.
With these changes, administrators will be able to change the application label, force the application to launch without being prime, and/or initially place the application on a selected set of PEs (allowing it to later be migrated).
External GRM queue priority
Applications are generally launched in FIFO order unless an application lower on the list will fit into unoccupied PEs. This change would allow sites to externally set the ordering priority of applications in the GRM queue via system call and possibly mpprun(1) administrator options
We now describe how one site, NERSC, has achieved high system utilization using psched under 2.0.4 with some 2.0.5 beta software. During a two week test of the psched software the site achieved 92% utilization in the APP region under a normal production workload as measured by SAR user plus system time. This included 5 hardware incidents in which the system had to be rebooted or degraded to warm-boot failed PEs. The system continues to perform at high utilization.
NERSC is the National Energy Research Scientific Computing Center and is funded by the U.S. Department of Energy, Office of Science. It is located at Lawrence Berkeley National Laboratory in Berkeley California. NERSC has a 25 year history of providing high performance computing to the DOE community. It was founded at the Lawrence Livermore National Laboratory in 1974 as the Magnetic Fusion Energy Computer Center and moved to Berkeley in 1996. The center provides computational resources to DOE programs in the fields of Fusion Energy, High Energy and Nuclear Physics, Basic Energy Sciences, Biology and Environmental Research and Computational and Technology Research. NERSC currently serves approximately 2500 users from major universities and government laboratories across the country.
The NERSC T3E, named "mcurie", is a T3E 900 with 696 processing elements. In its current configuration, mcurie has 644 application PEs, each with 256 MB of memory. It has a 411 GB swap space and a 625 GB checkpoint file system, each composed of 5 disk partitions with each partition consisting of 5 or 6-way striped DA308 disk arrays. This configuration was designed for speed when checkpointing jobs and for swapping during psched rank switches. It has a 1.5 TB scratch file system and seven 27 GB home file systems under DMF control. The large file systems, including scratch and checkpoint, are controlled by "remote mount" file servers. A brief history of NERSC T3E hardware is listed in Table 1. Pierre was a second, smaller system in general use until it was merged with mcurie in October of 1998. The center also operates six J90 SE systems which provide traditional parallel vector computing cycles.
| System Name | Type | PEs | APP PEs | Date | Comment |
| Mcurie | T3E-600 | 136 | 128 | 9/96 | Initial System |
| Pierre | T3E-600 | 104 | 96 | 12/97 | Initial System |
| Mcurie | T3E-900 | 544 | 480-512 | 8/97 | Phase II |
| Pierre | T3E-900 | 152 | 128 | 6/98 | Upgrade |
| Mcurie | T3E-900 | 696 | 644 | 10/98 | Merge with Pierre |
The NERSC T3E is used for application development, medium-sized capacity-based computing and large-scale "capability" problems. User codes include applications from chemistry, materials science, fusion research, geophysics, high energy nuclear physics, biology, climate modeling, astrophysics and fluid dynamics. The data shown in Table 2 indicate that the current workload is diverse and dynamic. A large number of small, short-running development applications are run on the system; it supports a steady flow of medium-sized applications; and 9 percent of the total machine resources have been consumed by applications requiring more than 128 processing elements.
|
App Size (PEs) |
% of All Apps |
% of PE Hours |
|
2-16 |
55.8 |
6.5 |
|
17-64 |
38.1 |
55.7 |
|
65-128 |
4.8 |
28.7 |
|
129-512 |
1.3 |
9.1 |
|
App Run Time |
% of All Apps |
% of PE Hours |
|
0-10 min |
55.7 |
1.1 |
|
10-30 min |
23.2 |
10.4 |
|
0.5-3.5 hr |
16.9 |
48.7 |
|
3.5-12.0 hr |
4.1 |
39.8 |
It is NERSC's goal to provide a system that will satisfy these three classes of users, as well as its DOE sponsors, who want to insure that this expensive resource is used efficiently. The site scheduling goals are:
These are competing goals. It is easy to efficiently schedule a system by running a large number of small jobs. The psched load balancer has been a stable product for quite some time and will consolidate unused PEs such that small and medium-sized jobs can get reasonable throughput. Scheduling large jobs while trying to minimize idle PEs is difficult because small applications can easily block the launch of a large application. Interactive loads are unpredictable and can block production work, especially large jobs. We will discuss how NERSC attempted to achieve these goals prior to the release of 2.0.4 and how they have configured their system to satisfy these goals under 2.0.4.
At NERSC, the batch system consists of NQE, NQS and a collection of PERL scripts that dynamically control the NQS configuration.
The site uses NQE as a holding pen for incoming requests. The NQE scheduler has been modified so that different LWS limits apply to the production and debug pipe queues. Each user is allowed up to three requests in the NQS production queues at any point in time. In addition, each user can have at most one simultaneous request in the debug queues.
The production batch queues are configured based on MPP PE limits and are shown in Table 3. The gc128 and gc256 queues are restricted to designated grand challenge users who are guaranteed a certain percentage of the machine resources.
|
Queue |
PE Limits |
Time Limits |
Priority |
Restriction |
|
pe512 |
512 |
4 hr |
45 |
none |
|
gc256 |
256 |
12 hr |
41 |
GC Users Only |
|
gc128 |
128 |
12 hr |
40 |
GC Users Only |
|
pe256 |
256 |
4 hr |
30 |
none |
|
long128 |
128 |
12 hr |
27 |
none |
|
pe128 |
128 |
4 hr |
25 |
none |
|
debug_med |
128 |
10 min |
29 |
none |
|
debug_sm |
32 |
30 min |
23 |
none |
|
pe64 |
64 |
4 hr |
20 |
none |
|
pe32 |
32 |
4 hr |
15 |
none |
|
pe16 |
16 |
4 hr |
10 |
none |
| Schedule | Configuration | Active Queues |
| 00:00 - 03:00 | Full Machine | pe512 (pe64, pe32 for backfill) |
| 03:00 - 06:30 | Batch Preferred | pe256, long128, pe128 and smaller |
| 06:30 - 19:00 | Regular | pe128, long128 and smaller |
| 19:00 - 24:00 | Grand Challenge | gc256, gc128 (pe64, pe32 backfill) |
The only feature of psched that NERSC used in production prior to UNICOS/MK 2.0.4 was the load balancer. Extensive dedicated testing and a live exposure test convinced the site that the gang scheduling software was simply too unstable to run in a production environment. In order to control the interactive workload, NERSC configured the APP region into two subregions, Batch and Mixed, with the GRM attributes specified in Table 5:
| Name |
PE Range |
Min | Max | Service | Time In Effect |
| Batch |
0-511 |
2 |
512 |
batch | always |
| Mixed |
512-644 |
2 |
64 |
login | 06:00-18:00 M-F |
| Mixed |
512-644 |
2 |
64 |
all | 18:00-23:00 M-F, 03:00-06:00 M-F, 03:00-23:00 S-S |
| Mixed |
512-644 |
2 |
64 |
batch | 23:00-03:00 everyday |
Unfortunately, this system configuration required that the site run with two psched domains, one for each region. Since psched is unaware of the GRM PE attributes, running the load balancer in a single domain with mixed GRM attributes would cause regular and repeated migration failures as psched would attempt to migrate a job into a location that GRM would not allow. Similarly, GRM is unaware of the psched domains and would launch an application at the location in the torus with the best match based on the attributes of the application and the PEs. This would often result in an application being launched on a range of PEs that intersected the boundary of the two domains. Neither domain would claim responsibility for such an application because it was not contained entirely within the confines of either domain. Such applications would never get migrated to better locations unless moved manually using the "migrate" command.
The configuration philosophy was to run interactive and some small batch jobs (when allowed) in the Mixed region. The site attempted to control this by setting the "close_max" precedence value high enough so that small jobs would be more likely to launch into the Mixed region. Even with this, the system would often get into a state where a large job was waiting to launch and the system had enough available PEs overall, but they were distributed throughout both the Batch and Mixed regions. Psched could not migrate applications between domains so large jobs would stall in a GRM wait state while large numbers of PEs would sit idle.
NERSC wrote a PERL "torus packing" script to detect and possibly correct these situations. If an application intersected both psched domains the script would attempt to migrate the application into the Mixed region and, if unsuccessful, into the Batch region. If the script detected a large batch job stuck in a GRM wait state, it would attempt to migrate small jobs from the Batch region into the Mixed region. This process was not always successful, depending on the existing job mix and how heavily the Mixed region was being used by interactive work.
Another problem the site experienced was job size entropy. Immediately after checkpointing the system to change queue configurations, the Batch region would be empty. In this state it was easy for NQS and GRM to run large applications. Over time, the job mix would shift from running large applications to small applications. This would usually result when a non-optimally sized application would run in the larger queues. For example, a 108 PE application running in the pe128 queue would make room for NQS to schedule a small 20 PE application. After the 108 PE application completed only 108 or smaller applications would be selected. Generally a set of 64 PE, 32 PE and 8 PE applications would be launched and 128 PE applications would be starved. To resolve this problem, NERSC wrote a "de-fragment" script that would stop the small queues, checkpoint a selected collection of smaller jobs and allow a larger job to start. This script was run manually, usually once or twice a day, to keep the large job throughput reasonable.
One of the NERSC systems group staff members, Brent Draney, took it upon himself to manually monitor and adjust the workload on the the system by migrating jobs and running the de-fragment script. Brent, who was referred to as "B-sched" by the site staff, also had a cron job send him an electronic page when the system idle time exceeded a certain level. It was because of this constant manual intervention that the system utilization and large queue turnaround values were as high as they were during this time period.
This configuration achieved the goal of managing the interactive workload on the system but did not really achieve the other site goals of minimizing idle time and queue turnaround without extensive automated and manual intervention.
NERSC upgraded to UNICOS/mk 2.0.4 in March 1999. The psched software was put through a series of tests in non-production, dedicated timeslots and proved to be robust and stable. Within two weeks of the upgrade mcurie was re-configured to use a single uniform 644 PE APP region with one psched domain. The GRM configuration was set with app_max=1 and abs_app_max=2. This allowed at most one non-prime application on a PE with at most two applications per PE overall (at least one must be prime). Psched has been configured to run the load balancer, the gang scheduler and the prime job feature of the resource manager.
The site also began running a beta version of the 2.0.5 GRM service limits. NERSC requested this feature in a design SPR. It allows the site to limit the total interactive workload to a configurable value - 132 PEs during the day and 4 PEs during the midnight hours (23:00-03:00). GRM will not launch an interactive application if doing so would cause the total interactive load on the system to exceed this value. The blocked applications are held in the GRM wait queue. In order to provide a responsive interactive system for code development, NERSC runs all interactive sessions as "prime" jobs between the hours of 05:30 and 22:00.
The NQS configurations were modified to over-subscribe the system with a global MPP PE limit of 832. In addition, the NQS scripts and configuration files were modified to allow jobs in selected queues to run with prime status. Each configuration specifies which queues are allowed to run prime jobs and the total amount of prime batch work allowed at any point in time. NERSC uses this to prime jobs in the large queues. Since prime jobs not only preempt non-prime work but also have GRM launching priority, this is an effective mechanism to keep large jobs running on the system, reversing the effects of job size entropy.
The torus packing scripts, manual migrations and "B-sched" are no longer in operation. The system is much simpler to manage and utilization has improved substantially. To everyone's delight, during a formal acceptance of the psched software, the system ran for two weeks with an average utilization of greater than 92% based on sar user plus system time in the APP region. In one 24 hour period, the site averaged 95% utilization.
NERSC has found that if the system has sufficient work in the NQS queues, they can easily achieve greater than 90% sustained utilization with this configuration. The site also feels they can improve upon this by enhancing the NQS control script.
NERSC users are given an allocation based on PE connect hours. As part of the accounting system, a database of all MPP accounting records is kept. The graph in figure 5 shows the PE connect time in hours per day broken down into application size. The data has been smoothed with a seven-day moving average. The time used by NERSC staff is not included and no effort was made to adjust for downtime or system dedicated time. Using this data, Table 6 shows the average utilization by connect time before the 2.0.4 upgrade, since the upgrade, and since the system was re-configured to its current state.
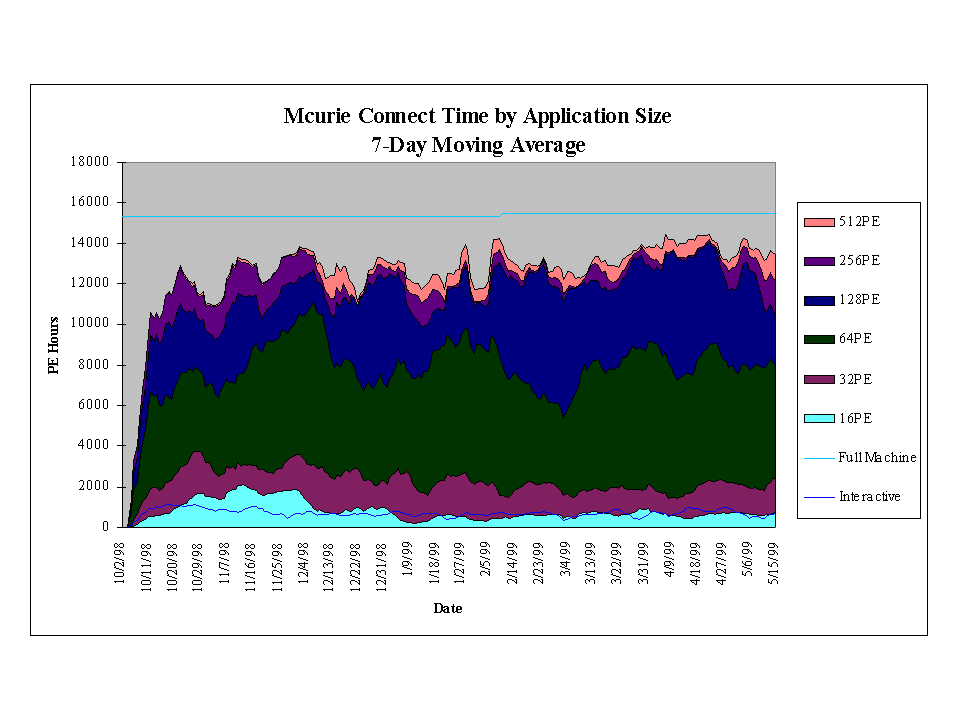
|
Dates |
Utilization | Comments |
| 10/01/98 - 03/04/99 |
78.9% |
Prior to 2.0.4 |
| 03/05/99 - 03/24/99 |
83.4% |
Since 2.0.4 |
| 03/25/99 - 05/10/99 |
90.0% |
Current Configuration |
Using the ability to prime large batch jobs NERSC has been able to reduce the queue wait times for the large queues. The graph in figure 5 shows the monthly average queue wait times since October 1998. The wait times are now consistent across the queues and are under 16 hours, except for the long128 queue which has a 12 hour time limit and a run limit of one. The pe16 queue is a recent addition for which historical data is not available.
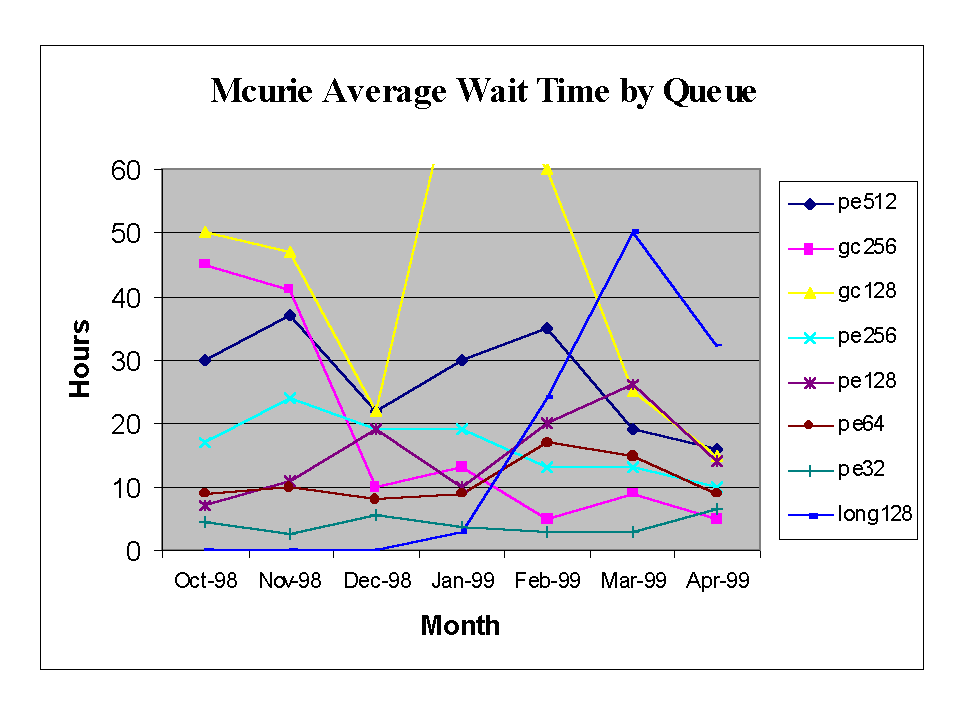
Clearly, NERSC's goals of minimizing idle time, managing the interactive workload and providing even queue turnaround are being met.
The improved scheduling characteristics provided by psched and GRM in UNICOS/mk 2.0.4 have prompted NERSC to pursue several further goals in scheduling their T3E.
The current release of psched has demonstrated much greater robustness and reliability. As a result of these improvements, NERSC is planning more extensive tests of gang scheduling to see if further efficiencies can be attained with NERSC's dynamic workload. Setting the GRM attribute "app_max=2" and using NQS and interactive service limits to control the total volume of work on the system should allow the load balancer to align applications in a more optimal distribution on the torus.
Improved turnaround for jobs using large (>64) numbers of PEs make it feasible to develop large debug