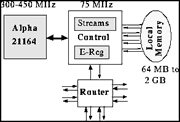
Figure 1: Block diagram of a Cray T3E node
The Cray T3E [Crag,ABGS97,ABH97,And00] is a distributed-memory massively-parallel processing system. It consists of up to 2,048 processing elements (PEs) built from a DEC Alpha 21164 EV 5.6 RISC microprocessor, a system control chip, up to 2 GB of local memory with 1.2 GB/s bandwidth, and a network router. A block diagram of a Cray T3E node is shown in figure 1. The system logic runs at 75 MHz, and the processor runs at some multiple of this.
The DEC Alpha 21164 microprocessor is capable of issuing four instructions per clock period, of which one may be a floating-point add and one may be a floating-point multiply. In the latest model Cray T3E-1200E each PE runs at 600 MHz giving a peak performance of 1200 Mflop/s per PE and an aggregated peak performance of 2.4 Tflop/s for a fully equipped system with up to 4 TB of central memory. The DEC Alpha processor provides two cache levels on chip: 8 KB first-level instruction and data caches and a unified, three-way associative, 96 KB second-level cache. The on-chip caches are kept coherent with local memory through an external backmap, which filters memory references from remote nodes and probes the on-chip caches when necessary to invalidate lines or retrieve dirty data.
The local memory bandwidth is enhanced by a set of six hardware stream buffers which automatically detect consecutive references to multiple streams, even if interleaved, and pre-fetch additional cache lines down each stream. Although there is no board-level cache on a Cray T3E node, the stream buffers can achieve much of the benefit of a large, board-level cache for scientific codes at a small fraction of the cost.
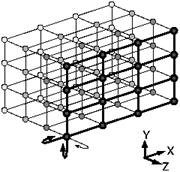
The processing elements are tightly coupled by a scalable three-dimensional bi-directional torus with a peak interconnect speed of 650 MB/s in each direction. An illustration of the Cray T3E torus interconnect is shown in figure 2. All remote communication and synchronization is done between external registers (E-registers) and memory to provide support for latency hiding and non-unit-stride memory accesses by gathering up single words that can then be loaded stride-one across the microprocessor bus system.
The GigaRing I/O system performs input/output through multiple ports onto one or more GigaRing channels. Each GigaRing interface has a maximum bandwidth of 500 MB/s with an aggregated peak I/O bandwidth of up to 128 GB/s.
The Cray T3E runs UNICOS/mk [Crai], a scalable version of the UNICOS operating system. UNICOS/mk is divided into a micro-kernel and servers and it is distributed among the T3E system PEs and provides a global view of the computing environment in a single system image to simplify system-wide management of resources. Global servers provide system-wide operating system capabilities, such as process management and file allocation.
The Cray T3E Programming Environment [Crah] provides an integrated set of application development tools like optimizing compilers, parallel libraries, a debugger (Cray TotalView Debugger), and performance analysis tools (MPP Apprentice, PAT). The Programming Environment includes compilers for Fortran 90, C, and C++. Each compiler supports explicit parallel programming through the Cray Message Passing Toolkit (MPT), which includes implementations of the standard PVM and MPI libraries and the Cray Shared Memory Access Library to deliver fast inter-processor communication. The Cray Fortran 90 compiler also supports implicit parallel programming based on Co-Array Fortran, High Performance Fortran (HPF), and CRAFT.
Explicit parallelism through message passing is a programming paradigm which is widely used on parallel computers, especially on scalable systems with distributed memory and on workstation networks. In addition to the well-known Message-Passing Interface (MPI) there exist older standards like the Parallel Virtual Machine (PVM) and proprietary message passing protocols like the Cray Shared Memory Access Library (SHMEM). The Cray T3E supports all three of these message-passing paradigms.
The Cray Message Passing Toolkit [Craf] supports inter-process data exchange for applications that use concurrent, cooperating processes on a single host or on multiple hosts. Data exchange is done through message passing, which means the use of library calls to request data delivery from one process to another or between groups of processes. The MPT package contains the following components:
Logically shared, distributed memory (SHMEM) message passing routines
Message Passing Interface (MPI)
Parallel Virtual Machine (PVM)
The Cray Shared Memory Access Library [Craa,Crac] supports distributed programming through message passing by providing one-sided communication routines (that is, one processing element (PE) can send or receive data directly to or from another PE without interfering with the remote PE). Supported operations include remote data transfer, atomic swap, work-shared broadcast and reduction, and barrier synchronization.
Data objects are passed by address to SHMEM routines. They can be arrays or scalars. Target or source arrays that reside on the remote processing element (PE) are typically identified by passing the address of the corresponding data object on the local PE. The existence of a corresponding data object locally implies that a data object is symmetric. Most uses of SHMEM routines employ symmetric data objects, but on Cray MPP systems, another class of data object, asymmetric accessible data objects, can also be passed to SHMEM routines.
Some SHMEM routines are classified as collective routines because they distribute work across a set of PEs. They must be called concurrently by all PEs in the active set.
The following fragment shows the code for the dot product function as a simple example for a reduction operation using Shared Memory Library routines:
FUNCTION dot_prod(n,x,y)
! computes the dot product x*y of two vectors x and y of length n
! using the Cray Shared Memory Library
INCLUDE 'mpp/shmem.fh'
REAL :: dot_prod
INTEGER, INTENT (IN) :: n
REAL, INTENT (IN) :: x(n), y(n)
REAL :: pwrk(shmem_reduce_min_wrkdata_size)
INTEGER :: psync(shmem_reduce_sync_size)
REAL global_sum, sum
INTEGER :: i, nprocs
EXTERNAL shmem_barrier_all, shmem_real8_sum_to_all
! calculate partial sums locally
sum = 0.
DO i = 1, n
sum = sum + x(i)*y(i)
END DO
! calculate global sum using a SHMEM reduction routine
nprocs = num_pes()
CALL shmem_barrier_all
CALL shmem_real8_sum_to_all(global_sum,sum,1,0,0,nprocs,pwrk,psync)
dot_prod = global_sum
END FUNCTION dot_prod
MPI [Pac96] is a standardized and portable message-passing system designed to function on a wide variety of parallel computers. The MPI standard defines the syntax and semantics of a core of library routines useful to a wide ranges of users writing portable message-passing programs in Fortran, C, or C++. MPI-1 was released in summer 1994. Since then, the MPI specification has become the leading standard for message-passing libraries for parallel computers. Implementations exist for a wide variety of platforms, often available as free implementations [HSS98] or as part of the standard system software [Crad]. There are also implementations available for heterogeneous networks of workstations and symmetric multiprocessors, for Unix and Windows NT, too.
The original MPI standard was created by the Message Passing Interface Forum (MPIF). The public release of version 1.0 of MPI was made in May 1994. The changes from version 1.0 to version 1.1 of the MPI standard were limited to corrections that were deemed urgent and necessary. Version 1.1 of MPI was released in June 1995 [MPI95].
The major goal of MPI is a degree of portability across different machines comparable to that given by programming languages like Fortran. This means that the same message-passing source code can be compiled and executed on a variety of machines as long as the MPI library is available. Though message passing is often thought of in the context of distributed-memory parallel computers, the same code can run well on a shared-memory parallel computer, too. It can also run on a network of workstations or as a set of processes running on a single workstation.
An efficient design goal of MPI was to allow efficient implementation across machines of differing characteristics and architectures. MPI only specifies what an operation does logically. As a result, MPI can be easily implemented on systems that buffer messages at the sender, receiver, or do no buffering at all. Implementations can take advantage of specific features of the communication subsystem of various machines. For example on machines with intelligent communication coprocessors, much of the message passing protocol can be offloaded to the coprocessor.
MPI was designed to encourage overlap of communication and computation, so as to take advantage of intelligent communication agents, and to hide communication latencies. This is achieved by the use of non-blocking communication calls, which separate the initiation of a communication from its completion.
MPI supports scalability through several design features. An application can create subgroups of processes which allows collective communication operations to limit their scope to the processes involved. Another technique used is to provide functionality that does not require local computation that scales as the number of processes. For example, a two-dimensional Cartesian topology can be subdivided into its one-dimensional rows or columns without explicitly enumerating the processes.
Version 1 of the MPI [GHLL+98,Gro99a] standard includes:
Point-to-point communication
Collective operations
Process groups
Communications domains
Process topologies
Environmental management and inquiry
Profiling interface
Bindings for Fortran and C.
The scope of MPI was limited in order to be able to address a manageable set of topics in time. Important topics that were deliberately omitted included: dynamic processes, input/output, and one-sided operations.
To promote the continued use of MPI and benefit a wide class of parallel applications, the MPI Forum met again in March 1995. The new MPI-2 standard [MPI97] includes significant extensions to the MPI-1 programming model, a number of improvements to the old MPI standard, and clarifications to parts of the MPI specification that had been subject to misinterpretation. Features added to MPI-2 [SOHL+98,Gro99b] are:
Dynamic process management
Input/output
One-sided operations
Bindings for C++.
The following fragment shows the code for the dot product function as a simple example for an MPI reduction operation:
FUNCTION dot_prod(n,x,y)
! computes the dot product x*y of two vectors x and y of length n
! using MPI
INCLUDE 'mpif.h'
REAL :: dot_prod
INTEGER, INTENT (IN) :: n
REAL, INTENT (IN) :: x(n), y(n)
REAL global_sum, sum
INTEGER :: i, status
EXTERNAL mpi_allreduce, mpi_barrier
! calculate partial sums locally
sum = 0.
DO i = 1, n
sum = sum + x(i)*y(i)
END DO
! calculate global sum using MPI reduction routine
CALL mpi_barrier(mpi_comm_world,status)
CALL mpi_allreduce(sum,global_sum,1,mpi_real,mpi_sum,&
mpi_comm_world,status)
dot_prod = global_sum
END FUNCTION dot_prod
PVM [Gei94,Crae] is a unified framework for the development of parallel programs. PVM enables a collection of heterogeneous computer systems to be viewed as a single parallel virtual machine. PVM transparently handles all message routing, data conversion, and task scheduling across a network of computer architectures.
The PVM computing model accommodates a wide variety of application program structures. The programming interface is straightforward, thus permitting simple program structures to be implemented in an intuitive manner. The user writes his application as a collection of cooperating tasks. These tasks access PVM resources through a library of standard interface routines. The routines allow the initiation and termination of tasks across the network as well as communication and synchronization between tasks. The PVM message-passing primitives are oriented towards heterogeneous operation, involving strongly typed constructs for buffering and transmission. Communication constructs include those for sending and receiving data structures as well as high-level primitives such as broadcast, barrier synchronization, and global sum.
PVM tasks may possess arbitrary control and dependency structures. At any point in the execution of a concurrent application, any task in existence may start or stop other tasks or add or delete computers from the virtual machine. Any process may communicate and/or synchronize with any other. Any specific control and dependency structure may be implemented under the PVM system by appropriate use of PVM constructs and host language control-flow statements. Therefore, the PVM system has gained widespread acceptance in the high-performance scientific computing community.
The following fragment shows the code for the dot product function as a simple example for a PVM reduction operation:
FUNCTION dot_prod(n,x,y)
! computes the dot product x*y of two vectors x and y of length n
! using PVM
INCLUDE 'fpvm3.h'
REAL :: dot_prod
INTEGER, INTENT (IN) :: n
REAL, INTENT (IN) :: x(n), y(n)
REAL sum
INTEGER :: i, status
EXTERNAL pvmfbarrier, pvmfreduce
! calculate partial sums locally
sum = 0.
DO i = 1, n
sum = sum + x(i)*y(i
END DO
! calculate global sum using a PVM reduction routine
CALL pvmfbarrier(pvmall,0,status)
CALL pvmfreduce(pvmsum,sum,1,real8,0,pvmall,0,status)
dot_prod = sum
END FUNCTION dot_prod
Whereas explicit parallelism needs expensive hand-coding for the message-passing routine calls, implicit parallelism offers an easier way for existing serial codes. Usually a few directives and code modifications are sufficient to transform a serial program to a serial one. In addition, directives for implicit parallel programs are often treated as comments and therefore ignored by serial compilers which allows the modified programs to be used on serial machines.
For the Cray T3E the following implicit parallel programming models are available:
High Performance Fortran (HPF)
Co-Array Fortran
CRAFT
High Performance Fortran [KLS+94,] is an informal language standard for extensions to Fortran 90 which simplifies the task of programming data parallel applications for distributed memory machines. HPF provides directives for specifying how data are to be distributed over the local memories of a distributed-memory message-passing machine, a workstation network, or the caches of a shared-memory machine. The central idea of HPF is to augment a standard Fortran program with directives that specify the distribution of data across disjoint memories. The HPF compiler [PGI98a,PGI98b,PGI98c] handles the partitioning of the data according to the data distribution directives, allocating computation to processors according to the locality of the data references involved, and inserting any necessary data communication in an implementation dependent way using message passing or shared memory communication. HPF also provides language extensions and directives for expressing data-parallelism and concurrency. On many architectures the performance of an HPF program will depend critically on its data distribution, and to a lesser extent on its use of the facilities for expressing data-parallelism and concurrency.
HPF was developed between March 1992 and May 1993 by the High Performance Fortran Forum. The formal language definition is contained in the High Performance Language Specification [HPFF93].
A revised language specification HPF 1.1 [HPFF94] was produced in 1994 containing corrections, clarifications and interpretations of HPF 1.0.
A new base standard HPF 2.0 [HPFF97] was produced in 1997 which is now based on full Fortran 95.
The following fragment shows the code for the dot product function as a simple example for a reduction operation in HPF:
PROGRAM cug_demo
INTEGER, PARAMETER :: n = 1000
REAL :: sum
REAL :: x(n), y(n)
!HPF$ DISTRIBUTE x(BLOCK)
!HPF$ ALIGN y(:) WITH x(:n)
REAL :: sum
sum = dot_prod(n,x,y)
CONTAINS
FUNCTION dot_prod(n,x,y)
! computes the dot product x*y of two vectors x and y of length n
! using High Performance Fortran
REAL :: dot_prod
INTEGER, INTENT (IN) :: n
REAL, INTENT (IN) :: x(n), y(n)
!HPF$ INHERIT x, y
REAL sum
INTEGER :: i
sum = 0.
!HPF$ INDEPENDENT, REDUCTION (sum)
DO i = 1, n
sum = sum + x(i)*y(i)
END DO
dot_prod = sum
END FUNCTION dot_prod
END PROGRAM cug_demo
Please note that the calculation of the global sum is very expensive if the loop is coded straightforward as the memory access to the global variable sum has to be synchronized and the loop has to be serialized by the compiler! Therefore, a REDUCTION directive is used to avoid the serialization of the loop.
Co-Array Fortran [NR98] is an extension to Fortran 95 for parallel processing which strictly follows the SPMD paradigm. A Co-Array Fortran program is interpreted as a replication of a serial program where all copies are executed asynchronously. Each program copy has its own set of data objects. In Co-Array Fortran the array syntax of Fortran 95 is extended with additional trailing subscripts to represent any data access across images. References without additional subscripts are to local data. Intrinsic procedures synchronize images, return the number of images, and return the index of the current image.
The following example shows the declaration of two one-dimensional arrays x and y in Co-Array Fortran which are replicated on every image of the program:
REAL, DIMENSION (n)[*] :: x, y
A replication of array y on processor p is referenced in the form
y(:)[p]
Thus, the assignment
x(:) = y(:)[p]
simply copies the image of array y from processor p to a local array x on each processor. Its effect is similar to a one-sided shmem_get without the messy message-passing calls.
The following fragment shows the code for the dot product function as a simple example for a reduction operation in Co-Array Fortran:
FUNCTION dot_prod(n,x,y)
! computes the dot product x*y of two vectors x and y of length n
! using Co-Array Fortran
REAL :: dot_prod
INTEGER, INTENT (IN) :: n
REAL, INTENT (IN) :: x(n)[*], y(n)[*]
REAL sum[*]
INTEGER :: i, p
! calculate partial sums locally
sum = 0.
DO i = 1, n
sum = sum + x(i)*y(i)
END DO
! calculate global sum in first image
CALL sync_images
IF (this_image()==1) THEN
DO p = 2, num_images()
sum = sum + sum[p]
END DO
END IF
! broadcast global sum from first image to other images
CALL sync_images
IF (this_image()>1) THEN
sum = sum[1]
END IF
! return global sum
dot_prod = sum
END FUNCTION dot_prod
More examples can be found in [NR98]. Co-Array Fortran is built into the Cray CF90 Compiler [Crab].
CRAFT (Cray Adaptable Fortran) is built into the PGHPF compiler for the Cray T3E. The main difference between CRAFT and HPF is that a CRAFT program run per default in parallel mode and serial program sections have to be declared explicitly, whereas an HPF program runs in serial mode except for parallel loops.
We have shown that the Cray T3E supports a large range of parallel programming paradigms both for implicit and explicit parallelism. Implicit parallel programming models reduce the effort to transfer an existing serial application to a parallel platform and provide for clearer program codes, often for the price of less performance gain. In contrast, explicit parallel programming models are unbeatable with respect to performance but require a larger effort for code development transfer.
http://www.cray.com/products/systems/crayt3e/paper1.html
Hans-Hermann Frese is Chairman of the CUG Programming Environments SIG. He is a staff member of the Supercomputing Department at the Konrad-Zuse-Zentrum für Informationstechnik Berlin (ZIB). His interests also include the evaluation of supercomputer systems, tools, and compilers.
