Chris Smith, Bill McMillan, and Ian Lumb
Platform Computing Corporation, Markham, Ontario, Canada
email: [csmith,billm,ilumb]@platform.com
ABSTRACT: Explicit job topology requirements provide a challenge for traditional batch queueing environments which aren't aware of the ccNUMA characteristics of the Origin family of systems. This paper describes the integration of the LSF Distributed Resource Management framework with the IRIX cpuset API. The integration needs to address the issues of how to place jobs within a cpuset, how to decide which CPUs should be included in a cpuset based on the cpu and memory requirements of the job, and how to decide whether or not a particular machine can fulfill the job topology requirements at the time, or whether the job needs to wait for the topology requirements to be satisfied. LSF system was enhanced to provide an external scheduler interface to support topology scheduling and a job execution plug-in interface to support the binding of jobs to cpusets.
Click here for this paper or slides in PDF format
The NUMA aspects of the machine are not completely transparent to the programmer, though. While allowing processes to make use of very large process address spaces, the latency introduced by the non-uniform memory access model has made job runtime very dependent on the combination of CPUs which a job is scheduled onto. It has been noted that parallel programs can suffer from unpredictable runtimes based on the location where the shared memory segments for the program reside. It is possible for program pages to reside ``far'' from the processing of the data due to the first-touch page placement algorithm employed by IRIX[2].
There are many tools provided for programmers by which they can analyze their program dependencies (perfex), employ optimization algorithms on page placement (automatic page migration), and request specific memory and process mapping to node boards (topology specification using dplace)[3].
While the use of these tools allows a programmer to optimally run a job on a NUMA machine, one programmer is typically not the only programmer to make use of a large configuration machine. When multiple programmers are contending for the memory and CPU resources of a computer, the goal of optimal job placement might conflict with the goal of optimally utilizing the machine's capabilities. In short, users will be competing for their share of the machine resources.
In order to address the contention over resources, systems will typically run resource management software to manage user access to the memory and CPUs of the system. SGI has provided some mechanisms to manage this issue[4]:
The problem with these mechanisms is that they are statically configured or configured ad-hoc. Miser queues are maintained by the system administrator and cannot be changed automatically to provide fairness between users, and cannot be changed automatically to rebalance the system between interactive and batch environments. Miser also doesn't attempt to address job topology requirements which can have a measureable impact on job performance.
Cpusets, on the other hand, can be created dynamically out of the available machine resources, but they aren't governed by any type of resource allocation policy that is evident in Miser and other resource managers.
In order to combine policy-based scheduling with enforcement of job topology and CPU requirements, we have implemented a topology aware scheduling mechanism for the LSF distributed resource manager.
The current form of the LSF scheduler sees SMP machines as a collection of a number of CPUs along with a large amount of shared memory. Scheduling is done based on the number of ``CPU slots'' which have already been allocated to jobs, along with the current runtime load on the machine, but there is not necessarily a direct mapping of an LSF ``CPU slot'' to an actual CPU since the LSF scheduler cannot enforce a ``CPU reservation'' without the aid of the operating system.
The use of the IRIX cpuset API allows LSF to enforce it's CPU allocations for jobs. Not only does the cpuset provide ``containment'' so that an eight CPU job will only run on eight CPUs, but it provides a ``reservation'' so that those eight CPUs are guaranteed to be available only for the job which they were allocated to.
In addition to this basic view of the SMP, LSF does not inherently understand the ccNUMA characteristics of the machine. Two hosts with an identical number of free ``CPU slots'' would be considered equivalent, even though the job's topology requirements might fit more readily onto one of the two hosts. This choice of host might have a significant impact on the runtime of the job.
In order to properly make use of the cpuset API on a large Origin class machine, LSF needs to understand how to properly choose the CPUs which will be in a cpuset. In some cases, it is better for a job to wait until the desired CPUs are available rather than be run on a set of CPUs which might increase the job runtime. Thus, the LSF scheduler needs to know how to decide whether a host can currently fulfill a job's topology requirements.
The ultimate goal of the LSF integration with cpusets is to provide a mechanism such that an LSF job may be run in a cpuset. This might be so that a job can guarantee some CPU affinity to support a job topology requirement, or in order to allow a job to have exclusive access to it's allocated CPUs, avoiding The effect of thread migration and cache flushes. The integration must also support a mix of jobs, some of which run in a cpuset and some of which don't.
We investigated three approaches to cpuset integration.
While the third approach is more complicated to implement, discussions with prospective cpuset users highlighted the importance of CPU placement for parallel jobs on Origin servers.
In order to integrate LSF with the cpuset mechanism we needed to identify the events during a job lifecycle where interaction is required. Five different key events were identified:
Underlying these requirements was the goal of making the scheme extensible. This was done so that future work on the cpuset mechanism, more optimized topology scheduling algorithms, or different underlying hardware topologies, could be done without needing to redesign or reimplement the framework supporting the NUMA scheduling.
The implementation of the cpuset integration according to the above design criterion was done using a set of different architectural modules which interacted with each other.
A daemon runs on each host which supports the cpusets. This daemon is responsible for keeping track of the machine's hardware graph, as well as the current allocation of cpusets. By having a current snapshot of the hardware graph and in-use CPUs in one place, there is a single decision point as to whether a particular topology can be satisfied. This daemon considers boot cpusets and cpusets manually created by the system managers, and adjusts its notion of CPU availability based on that information.
This daemon also performs the cpuset specific actions of allocation and deallocation (an operation which needs to be done as the root user). It supports protocol interfaces for performing queries, allocation and deallocations.
An external scheduling module was implemented to keep the specifics of NUMA aware scheduling external to the main LSF scheduling loop. The interface between the LSF scheduler and this external scheduler is a functional interface. Among other operations, there is an operation so that the LSF scheduler can ask ``does this host satisfy requirement X'' without needing to understand any details about X. Another operation is to sort the list of hosts which can satisfy the requirement by which one provides the ``best'' topology.
Essentially, the external scheduler acts as a ``request broker'', since it translates the user-supplied topology requirement to an availability query to a host's topology daemon, which then interprets the request and makes a reply.
LSF currently provides various site configuration hooks which are called during a job's execution lifecycle[5]. There is a pre-execution function, a ``job starter'' function (interposed between the slave batch daemon and the execution of the actual job), and a post-execution function. These mechanisms could have been used to implement the allocation, binding and deallocation of the cpuset, however this would have made the interface cumbersome for users wishing to perform other functions using these hooks.
A shared object is loaded into the slave batch daemon which provides entry points for pre and post job processing. One entry point is used to allocate a cpuset, one for binding the job to the cpuset, and another for deallocaing the cpuset. Using a shared object allows the implementation of these functions to change without requiring modifications to LSF's slave batch daemon.
The modules use various ways to communicate with each other in order
to implement the five actions identified in
section 3. The interactions are diagrammed in
figure 1 (on page ![]() ). The
numbers in the diagram are referenced in the interaction description
below.
). The
numbers in the diagram are referenced in the interaction description
below.
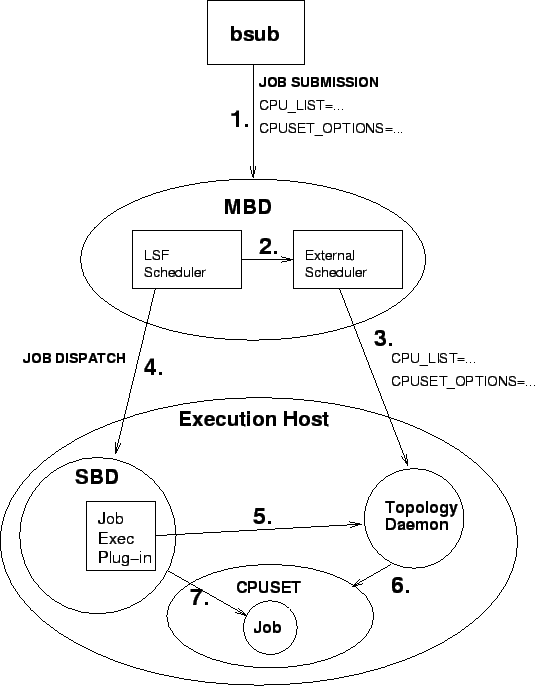
A job submission time (1 in the diagram), the user defines the topology requirement for the job by using the new ``-extsched'' command-line option to LSF's bsub command. This option attaches the topology requirement string to the job using the new bpost functionality from LSF 4.0. This attachment can then be read using the bread command (or the equivalent LSF library API).
An example of an LSF submission command which attaches a job (command-line ``command'') to an exclusive cpuset using CPUs 24 to 39 and 48 to 53. The MEMORY_MANDATORY option is specified to restrict memory allocations for the processes from the nodes on which the CPUs reside.
bsub -n 32 -extsched \ `CPU_LIST=..;CPUSET_OPTIONS=..'\ command where: CPU_LIST=24-39,48-53 CPUSET_OPTIONS=\ CPUSET_CPU_EXCLUSIVE\ |CPUSET_MEMORY_MANDATORY
In order to schedule the request, the LSF scheduler (MBD) calls into the LSF scheduler (2) which then queries the topology daemon on a host to see if it can satisfy the job's topology requirements (3). These requirements are ``bread'' from the job, and then passed in the query message. The topology daemon then responds whether or not it can schedule the job. Since the external scheduler queries are performed within the LSF scheduler's normal scheduling run, the topology daemon query only represents one ``filter'' for job candidate hosts. This means that the external scheduler will coexist with LSF's current scheduling algorithms and mechanisms, such as scheduling based on resource requirements (e.g. the job needs one gigabyte of memory), the preemption algorithm, fairshare, and CPU slot reservation, to name a few.
After the scheduling run, a job will have a list of hosts which can satisfy the topology requirement for the job. This list is then passed to the external scheduler, which then reorders the list based on the cpuset which has ``best'' topology available. For the best-fit algorithm this would be the cpuset which offers the shortest radius between CPUs in the cpuset.
Once the execution host has been selected, and the job has been dispatched to the slave batch daemon (SBD) on that host to run (4), the slave batch daemon will call a plug-in function to allocate the cpuset. This function will ask the topology daemon(5) to create the cpuset on behalf of the job(6). The LSF job id will be passed to the topology daemon so that the cpuset can be named using the unique LSF job id, thus allowing the later stages of the process to properly identify the cpuset. The topology requirements will also be ``bread'' again so that the topology daemon can allocate the proper set of CPUs.
Another plug-in function is then called to bind the job to the cpuset (7). This plug-in function needs to be called in a process which will ultimately be a parent for the entire job. Since it is called from the slave batch daemon, this can be guaranteed.
Lastly, once the job has completed and it's processes exited, a plug-in function is called to ask the topology daemon to deallocate the cpuset.
The use of IRIX cpusets with LSF has shown to have a positive effect on throughput benchmarks run by SGI in response to customer benchmark requests.
Once such benchmark consisted of a mix of 50 MPI jobs (one was a hybrid MPI/OpenMP job)[6]. The mix as provided by the customer (Mix A) was not to be changed (in terms of ordering and number of cpus), included some 5 minute sleeps during job submission, and was run on a 128 processor, 128 gigabyte Origin 3000 machine. 1
The ideal mix time (with no sleeps) was calculated to be 2:21:22, using the formula:
The LSF configuration used included a job slot limit at the host level of 128 (one slot per cpu). To reduce dispatch delays the JOB_ACCEPT_INTERVAL for the cluster was 0 (meaning multiple jobs could be dispatched to a host on one scheduling run), and NEW_JOB_SCHED_DELAY for the queue was set to 0 (so that a scheduling run would be initiated as soon as a job was accepted by LSF). When cpusets were used, they were created with the cpuset option CPUSET_MEMORY_LOCAL.
Running through LSF without the cpuset integration yielded a runtime of 4:19:01. Of note was the variance in runtime between two identical jobs, one which ran in 39:34.36 and one which ran in 8:17.02.
Running through LSF with the cpuset integration yielded a runtime of 2:51:06. The two identical jobs mentioned previously ran with much less variance. Job 1 in 8:08.39 and job 2 in 8:03.69.
Running the benchmark again without the sleeps yielded a runtime of 2:35:47.
See table 1 for the summary of results, and
table 2 (on page ![]() ) for a
breakdown of individual job runtimes with and without cpusets compared
to the ideal runtime.
) for a
breakdown of individual job runtimes with and without cpusets compared
to the ideal runtime.
|
A number of future enhancements can be made to the implemented topology scheduling framework:
We presented an architecture for topology aware scheduling within the LSF distributed resource manager, and the use of IRIX cpusets to enforce the topology and CPU allocation for jobs by the LSF scheduler. The integration was designed by examining which events during a job's lifecycle need to be modified to deal with the scheduling and allocation of cpusets, and discussed the architectural modules which implement the integration.
We found that it was very important to identify the events during a job's lifecycle where topology scheduling decisions and actions needed to be taken. By making this analysis, it was straightforward to design architectural components which could deal with each event, thus encapsulating each step in a smaller, more focused module, which was easier to implement.
The component approach also allowed us to design an external scheduler to extend the LSF scheduling capability. This was a better approach than ``hard-coding'' the understanding of ccNUMA architecture into the LSF scheduler, since the architecture may change, and is specific to a particular hardware and operating system platform. The external scheduler also provides the beginnings of a framework by which the LSF scheduler could be easily modified to support arbitrary external scheduling algorithms (not just NUMA schedulers), much improving LSF's extensibility.
As expected, the use of cpusets for running jobs decreased the runtime variability of parallel tasks. Moreover, the combination of LSF with cpusets yielded an improvement of at least 50% on a simple throughput benchmark, and with some submission improvement (no sleeps), the benchmark ran only 10% longer than the ideal mix time.
Finally, it is interesting to note the verification of some past LSF architectural improvements. The bpost/bread mechanism was introduced in LSF 4.0 in order to facilitate the integration of LSF with third-party software packages. By making use of this mechanism within the implementation of the external scheduler, we have verified the utility of the bpost/bread functionality, and set an example for how this functionality can be used.